Identifying the Saddle Point Problem in High-dimensional Non-convex Optimization (Mukund)
Non-Convex Optimization
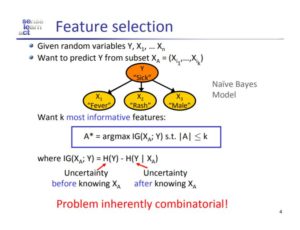
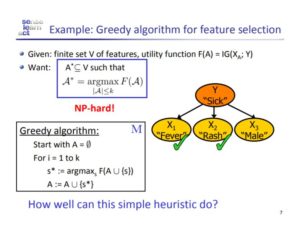
Non-convex optimization problems are any group of problems which are not convex (concave, linear etc.). These non-convex optimization problems are difficult to solve because non-convex functions have potentially many local minima and finding the global minima among all the local minima is hard. For this reason, solving such optimization problems are at least NP-Hard. Other reasons which make optimizing non-convex problems are
- the presence of saddle points
- very flat regions exhibited in the curvature
- the curvature of such functions can be widely varying.
Traditionally, methods like Gradient descent, Newton Methods which are used to solve convex optimization problems are used to solve non-convex optimization problems as well.
Saddle Points
Given a function f, a critical point is defined as the point in the function where the derivative of f becomes 0. Typically, critical points are either maxima or minima (local or global) of that function. Saddle points are special type of critical points where the slope becomes 0, but are not local extremum in both axes.
For example, in the graph  , the point (0,0) is the saddle point because the gradient at (0,0) is 0, but the point in neither a local maxima not a local minima.
, the point (0,0) is the saddle point because the gradient at (0,0) is 0, but the point in neither a local maxima not a local minima.
At this point, let us talk a bit more about critical points. The curvature of the function surrounding these critical points can tell us a lot about these critical points itself. The curvature of the function can be evaluated using the Hessian at these points. The eigen values of the Hessian at the critical point can describe the critical point.
- If the eigen values are all non-zero and all positive, then the critical point is local maxima
- If the eigen values are all non-zero and all negative, then the critical point is local minima
- If the eigen values are all non-zero and mix of both positive and negative values, then the critical point is saddle point
- If the Hessian matrix is singular, then the critical point is a degenerate critical point
Saddle Point Problem in High Dimensional Non-convex Problems
When a non-convex error function has a single scalar variable, there might be a lot of local maxima and local minima in the function but there is very negligible probability of occurrence of a saddle point. Whereas error functions with N scalar variables are likely to have more saddle points than local minima. In fact, as the dimensionality (N) increases, the number of saddle points increases exponentially. There have been many studies to prove this point. When dealing with high dimensional non-convex problems, which is the case with real world problems, we have to deal with these saddle points. The traditional methods like gradient descent and Newton methods perform poorly in presence of these saddle points. The gradient descent methods are repelled away from these saddle points, but the convergence is painfully slow. Whereas the Newton methods in an effort to speed up convergence, get attracted to these saddle points and do not converge on the local minima.
Dynamics of Optimization Algorithms around Saddle Points
To better understand the difficulty of existing optimization algorithms for high dimensional non-convex problems, it is helpful to understand how these algorithms behave near saddle points during the optimization process.
We can re-parameterize the critical points using the Taylor expansion so that they can be locally analysed. The Taylor expansion can be given as:
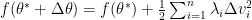
The step size that the gradient descent method uses is  . A step of the gradient descent method will always move in the right direction around the saddle point. If the eigen value is positive, we move towards that point in the direction of the negative curvature and hence the gradient descent method will always move away from the saddle points. The problem with gradient descent is the step size. Because gradients are proportional to corresponding eigenvalues, eigenvalues dictates how fast we move in each direction. If there is a large discrepancy in eigenvalues, the gradient descent will take very small steps.†It might take a very long time to move away form the critical point, if the critical point is a saddle point, or to the critical point if it is a minimum.
. A step of the gradient descent method will always move in the right direction around the saddle point. If the eigen value is positive, we move towards that point in the direction of the negative curvature and hence the gradient descent method will always move away from the saddle points. The problem with gradient descent is the step size. Because gradients are proportional to corresponding eigenvalues, eigenvalues dictates how fast we move in each direction. If there is a large discrepancy in eigenvalues, the gradient descent will take very small steps.†It might take a very long time to move away form the critical point, if the critical point is a saddle point, or to the critical point if it is a minimum.
The Newton method rescales the gradients in each direction with the inverse of the corresponding eigenvalue. The step size used in the Newton method is 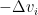 . If the eigenvalue is negative, the Newton method moves in the opposite direction to the gradient descent method due to the rescaling. This results in moving in the wrong direction around the saddle points and Newton methods instead of escaping the saddle point converge on them.
. If the eigenvalue is negative, the Newton method moves in the opposite direction to the gradient descent method due to the rescaling. This results in moving in the wrong direction around the saddle points and Newton methods instead of escaping the saddle point converge on them.
The trust region is a second order method, where the step size taken is  . This speeds up the convergence significantly and this method moves in the same direction as the gradient descent method, thus escaping the saddle points. It can also suffer the drawback of slow convergence sometimes if
. This speeds up the convergence significantly and this method moves in the same direction as the gradient descent method, thus escaping the saddle points. It can also suffer the drawback of slow convergence sometimes if  is too large.
is too large.
Attacking the Saddle Point Problem in High-dimensional Non-convex Optimization (Yufeng)
Problems with Stochastic Gradient Descent (SGD) and Newton Method
Based on our previous analysis, we know that saddle points are ubiquitous in high dimensional non-convex optimization problems. However, we are still uncertain about how modern optimizers would behave around these saddle points. Specifically, we would like to focus on Stochastic Gradient Descent (SGD) and Newton method here.
Suppose we have a function 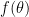 , in which
, in which  stands for the whole parameters of a model that we want to optimize. Besides, we have a saddle point
stands for the whole parameters of a model that we want to optimize. Besides, we have a saddle point 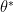 . Then we may approximate around this saddle point using second-order Taylor expansion by
. Then we may approximate around this saddle point using second-order Taylor expansion by
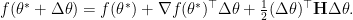
Since a saddle point is also a critical point, the second first-order term can be cancelled with  being a
being a  vector. Now let’s reparametrize
vector. Now let’s reparametrize 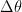 based on how it changes along orthonormal eigenvector directions of the Hessian matrix
based on how it changes along orthonormal eigenvector directions of the Hessian matrix  , i.e.,
, i.e., 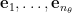 . Here
. Here 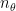 represents the number of eigenvectors for . Correspondingly, we also have eigenvalues
represents the number of eigenvectors for . Correspondingly, we also have eigenvalues 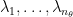 . Then the movement along eigendirections can be formulated as
. Then the movement along eigendirections can be formulated as
![\begin{aligned} \Delta \mathbf{v} &= \left[ \begin{array}{c} e_1^\top\\ \vdots\\ e_{n_\theta}^\top \end{array} \right] \Delta\theta \end{aligned}.](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++%5CDelta+%5Cmathbf%7Bv%7D+%26%3D++%5Cleft%5B++%5Cbegin%7Barray%7D%7Bc%7D++e_1%5E%5Ctop%5C%5C++%5Cvdots%5C%5C++e_%7Bn_%5Ctheta%7D%5E%5Ctop++%5Cend%7Barray%7D++%5Cright%5D++%5CDelta%5Ctheta++%5Cend%7Baligned%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Since a Hessian matrix should be both real and symmetric, with orthonormal eigenvectors, it can be represented by
![\mathbf{H} = [ e_1, \dots, e_{n_\theta} ] \Lambda \left[ \begin{array}{c} e_1^\top \\ \vdots \\ e_{n_\theta}^\top \end{array} \right],](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BH%7D+%3D+%5B+e_1%2C+%5Cdots%2C+e_%7Bn_%5Ctheta%7D+%5D+%5CLambda+%5Cleft%5B++%5Cbegin%7Barray%7D%7Bc%7D++e_1%5E%5Ctop+%5C%5C++%5Cvdots+%5C%5C++e_%7Bn_%5Ctheta%7D%5E%5Ctop++%5Cend%7Barray%7D++%5Cright%5D%2C&bg=ffffff&fg=000&s=0&c=20201002)
where  is the matrix with eigenvalues on the diagonal. Therefore, our Taylor expansion approximation can be expressed as:
is the matrix with eigenvalues on the diagonal. Therefore, our Taylor expansion approximation can be expressed as:
![\begin{aligned} f( \theta^* + \Delta\theta ) &= f(\theta^*) + \frac{1}{2} (\Delta\theta)^\top \overbrace{ [ e_1, \dots, e_{n_\theta} ] \mathbf{\Lambda} \left[ \begin{array}{c} e_1^\top \\ \vdots \\ e_{n_\theta}^\top \end{array} \right] }^{\mbox{ Orthonormal }} \Delta\theta \\ &= f(\theta^*) + \sum_{i=1}^{n_\theta} \lambda_i \Delta\mathbf{v}_i^2 \end{aligned}.](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D++f%28+%5Ctheta%5E%2A+%2B+%5CDelta%5Ctheta+%29+%26%3D+f%28%5Ctheta%5E%2A%29+%2B+%5Cfrac%7B1%7D%7B2%7D+%28%5CDelta%5Ctheta%29%5E%5Ctop%C2%A0%5Coverbrace%7B+%5B+e_1%2C+%5Cdots%2C+e_%7Bn_%5Ctheta%7D+%5D+%5Cmathbf%7B%5CLambda%7D+%5Cleft%5B++%5Cbegin%7Barray%7D%7Bc%7D++e_1%5E%5Ctop+%5C%5C++%5Cvdots+%5C%5C++e_%7Bn_%5Ctheta%7D%5E%5Ctop++%5Cend%7Barray%7D++%5Cright%5D+%7D%5E%7B%5Cmbox%7B+Orthonormal+%7D%7D+%5CDelta%5Ctheta+%5C%5C++%26%3D+f%28%5Ctheta%5E%2A%29+%2B+%5Csum_%7Bi%3D1%7D%5E%7Bn_%5Ctheta%7D+%5Clambda_i+%5CDelta%5Cmathbf%7Bv%7D_i%5E2++%5Cend%7Baligned%7D.&bg=ffffff&fg=000&s=0&c=20201002)
Based on the above reparametrization, we can now go forward with how SGD and Newton method stroll around the saddle point . First for SGD, the movement along a specific eigenvector 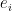 is defined as
is defined as
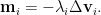
It’s worth mentioning that we are actually moving along the correct direction here. However, with  scaling before
scaling before  , eigenvalues of different magnitudes will result in different step sizes along eigenvector directions.
, eigenvalues of different magnitudes will result in different step sizes along eigenvector directions.
While for Newton method, the movement is quantified by
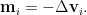
Although the magnitude of movement is forced to be the same by rescaling with the eigenvalues, negative eigenvalues can actually cause the resulting shift going in the opposite direction. This will unexpectedly increase the loss. Furthermore, since Newton method is originally developed to find roots of an equation, as it applied here on the first derivatives of the original objective function, it can eventually help to find all the critical points iteratively.
General Trust Region Methods
In order to tackle the saddle point problem, the authors defined a class of generalized trust region methods (GTRM), which is the extension of classical trust region method (CTRM). First of all, let’s look at how CTRM works. We’ll use second-order Taylor expansion (quadratic model) to approximate the original objective function

in which 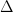 defines the radius of a trust region. While for their proposed GTRM, they made two changes:
defines the radius of a trust region. While for their proposed GTRM, they made two changes:
- The minimization of first-order Taylor expansion is allowed, which can in some way alleviate the difficulty of optimization;
- Original norm constraints on the step are relaxed, which is replaced by some hand-designed distance metrics.
With these extensions, the generalized trust region methods can be summarized as:
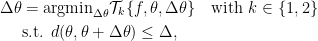
in which 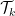 represents the
represents the  -th order Taylor expansion and
-th order Taylor expansion and  defines some distance metrics.
defines some distance metrics.
Attacking the Saddle Point Problem
Now let’s get back to how we should attack the saddle point challenge that can’t be completely solved by either SGD or Newton method. It would be straightforward to consider combining the advantages of both methods. Intuitively, we can just rescale the SGD movement by the absolute value of corresponding eigenvalues, i.e.,
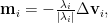
which uses the same rescaling as the Newton method but owns the property of moving in the correct eigendirection. However, there hasn’t been any mathematical justification of such designs before. Then we’ll need to answer two potential questions:
- Are we optimizing the same objective function, if we replace with
 which is the matrix obtained by taking the absolute value of each eigenvalue of ?
which is the matrix obtained by taking the absolute value of each eigenvalue of ?
- The above expectation might be true near the saddle points (or more generally the critical points), will it still work well when it’s far away from the critical points?
With the above concerns, the authors were able to show that this is actually a valid heuristic design based on their GTRM framework.
To begin with, a first-order Taylor expansion of the objective function is used as the main goal for optimization as:

which is just an affine transformation so that the minimum will always be negative infinity if there are no constraints on the input domain. Accordingly, we know the minimizer should lie on the boundary of the trust regions. Besides, we need to incorporate the curvature information into this optimization problem, which will have to come from inside the distance metric in constraints. Here in this paper, the authors restrict the trust region to be defined by how far the second-order Taylor expansion can be away from the first-order expansion. Formally, the distance constraint is defined as
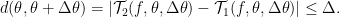
If expand the distance constraint, we can get

This quadratic problem will not be that easy to solve if is of high dimension. To circumvent this, the authors proposed a Lemma as shown below.
Lemma 1. Let 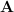 be a nonsingular symmetric matrix in
be a nonsingular symmetric matrix in 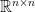 , and
, and 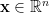 be any vector. Then it holds that
be any vector. Then it holds that 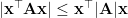 , where
, where 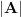 is the matrix obtained by taking the absolute value of each of the eigenvalues of .
is the matrix obtained by taking the absolute value of each of the eigenvalues of .
Proof. is nonsingular and symmetric 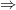
 are orthogonal. If they have been normalized, then
are orthogonal. If they have been normalized, then  .
.
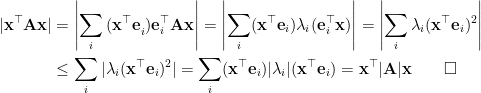
Therefore, instead of using the original constraint formula, we can fold  into the right-hand side distance upperbound and relax it a little bit as
into the right-hand side distance upperbound and relax it a little bit as

As we have already stated that such minimizer will always lie on the boundary of the trust region, we can further remove the inequality sign. Our final optimization problem becomes
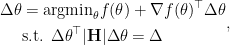
which can be solved analytically by Lagrangian multiplier method.
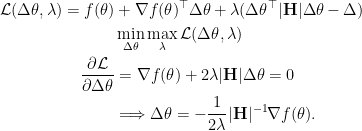
If the scalar in front is folded into learning rate, an update step would be

This is called saddle-free Newton method (SFN), which inherits the merits of both SGD and Newton method.
- It can move further (less) in the directions of low (high) curvature as compared to SGD.
- With always correct directions, it can move away from saddle points when the Hessian matrix is not positive definite.
However, the exact computation of a Hessian matrix would be infeasible in a high dimensional problem. To escape from exact computation, the authors introduce the Krylov subspace method, which tries to optimize upon another space that is much lower than the original space, i.e.,  . Here
. Here 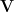 stands for the largest eigenvectors of the Hessian matrix. Such eigenvectors can be found efficiently through Lanczos iteration as stated in their paper. So it should be noted that now we are optimizing on the variable
stands for the largest eigenvectors of the Hessian matrix. Such eigenvectors can be found efficiently through Lanczos iteration as stated in their paper. So it should be noted that now we are optimizing on the variable  . Afterward, the new absolute value version Hessian matrix associated with this new space is calculated via eigendecomposition for
. Afterward, the new absolute value version Hessian matrix associated with this new space is calculated via eigendecomposition for  . Thereafter, Newton method similar steps can be applied iteratively. The authors also involve another step to determine the learning rate (step size) for their SFN method. The overall pseudocode is shown in Algorithm 1 in the following figure.
. Thereafter, Newton method similar steps can be applied iteratively. The authors also involve another step to determine the learning rate (step size) for their SFN method. The overall pseudocode is shown in Algorithm 1 in the following figure.

As we mentioned before, line 8 above is applied to search for a suitable learning rate  that can minimize current
that can minimize current 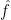 from our understanding. Then in line 9, it’s mapped back to the original parameter space () and the final update is done eventually.
from our understanding. Then in line 9, it’s mapped back to the original parameter space () and the final update is done eventually.
Experimental Validation
After theoretical analysis above, it’s essential to validate these results experimentally. In this section, the existence of saddle points, the effectiveness of SFN on the deep feed-forward neural network and recurrent neural network are elaborated through various experiments.
The Existence of Saddle Points in Neural Networks
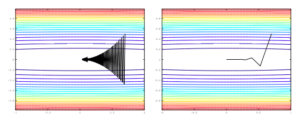
In order to compare with other popular optimizers like SGD and damped Newton method exactly, small neural networks on downsampled MNIST and CIFAR-10 are trained, which enables exact computation of updates. The experimental results are shown in the following figure.
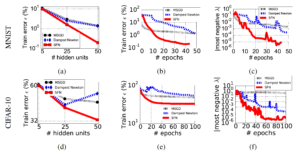
Based on the above figure, we can observe that:
- In (a) and (d), as the number of hidden units increases, our model become much more high-dimensional. It’s obvious that both SGD and damped Newton method get stuck around a hidden unit number of 25. However, for their proposed SFN, it’s still able to step into a region of much lower error. This indirectly indicates that the number of saddle points increases exponentially as the dimensionality of model increases.
- From (b) and (e) of learning curves plotted in terms of epochs, it confirms that SFN can evade away from saddle points and achieves a much lower training error. While for SGD and damped Newton method, both get trapped in regions where SFN does not.
- Finally, from (c) and (f), the evolution of the absolute value of most negative eigenvalue is shown, which shows that it moves more toward the right as we achieve a lower error. So we are gradually having a more positive definite Hessian matrix. This indicates a local minimum instead of saddle points, for which we have successfully escaped.
The Effectiveness of Saddle-Free Newton Method
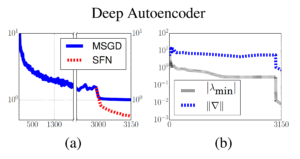
Furthermore, the authors tried to verify that their SFN method is also able to repel away from saddle points and achieves local minimum under deep neural networks. A seven-layer deep autoencoder is trained on the full-scale MNIST dataset, the approximate SFN jumps in after mini-batch SGD got stuck. The learning curve is shown in (a) of the figure below. We can also discover that after SFN is incorporated, the magnitude of the absolute value of the minimum eigenvalue and the norm of gradients have been reduced significantly.
Recurrent Neural Network Optimization
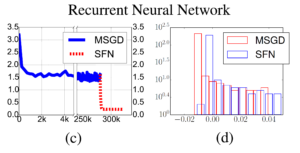
In the end, the authors tried to test if SFN is able to help training the recurrent neural network (RNN) if the training difficulty is caused by saddle points. A small RNN with  hidden units targeted for character-level language modeling is trained on the classical Penn Treebank dataset. Again SFN was used after SGD got trapped. A similar trend for learning curve is found as shown in (c) of the following figure. Furthermore, we can see in fig (d) that the Hessian matrix of the final solution found by SFN has much fewer negative eigenvalues as compared to ones found by mini-batch SGD.
hidden units targeted for character-level language modeling is trained on the classical Penn Treebank dataset. Again SFN was used after SGD got trapped. A similar trend for learning curve is found as shown in (c) of the following figure. Furthermore, we can see in fig (d) that the Hessian matrix of the final solution found by SFN has much fewer negative eigenvalues as compared to ones found by mini-batch SGD.






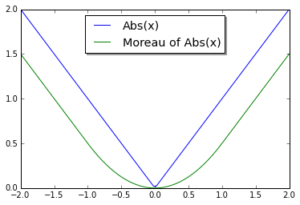
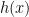




, take a step in the direction of the gradient of the differentiable part,
, evaluate the prox operator of the non-smooth part,


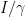




: Starting at
as:



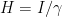
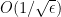
: Starting at
and
, evaluate:
as:




 . The minimization itself is performed using gradient descent -based methods, where the parameters are updated taking into account the gradient information.
. The minimization itself is performed using gradient descent -based methods, where the parameters are updated taking into account the gradient information.  . Many optimizations have been proposed over the years which try to improve the descent-based methods by incorporating various techniques utilizing the geometry , adaptive learning rates, momentum .
. Many optimizations have been proposed over the years which try to improve the descent-based methods by incorporating various techniques utilizing the geometry , adaptive learning rates, momentum . ).
).
 parameterized by
parameterized by  .
.
 .
. are the output of the recurrent neural network architecture parameterized by
are the output of the recurrent neural network architecture parameterized by  are weights associated with the predicted values of the optimizee for the last t time steps.
are weights associated with the predicted values of the optimizee for the last t time steps.  value is used in all the experiments. The optimizee parameters are updated with truncated back-propagation through time. The gradient flow can be seen in the computational graph below. The gradients along the dashed lines are ignored in order to avoid computing expensive second-derivative calculation.
value is used in all the experiments. The optimizee parameters are updated with truncated back-propagation through time. The gradient flow can be seen in the computational graph below. The gradients along the dashed lines are ignored in order to avoid computing expensive second-derivative calculation.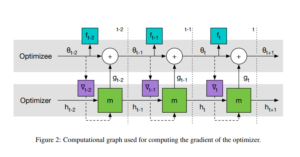
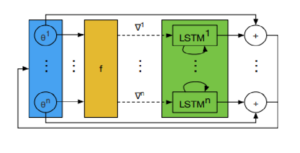
 directly,
directly,  the logarithm of the gradients and the sign of the gradients to the RNN architecture is passed to the coordinatewise architecture.
the logarithm of the gradients and the sign of the gradients to the RNN architecture is passed to the coordinatewise architecture.
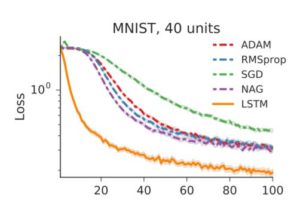

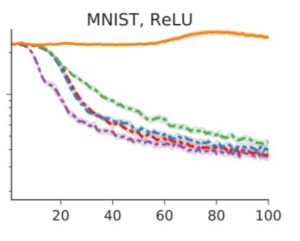

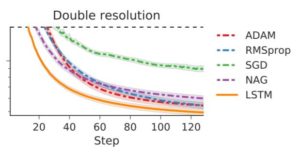
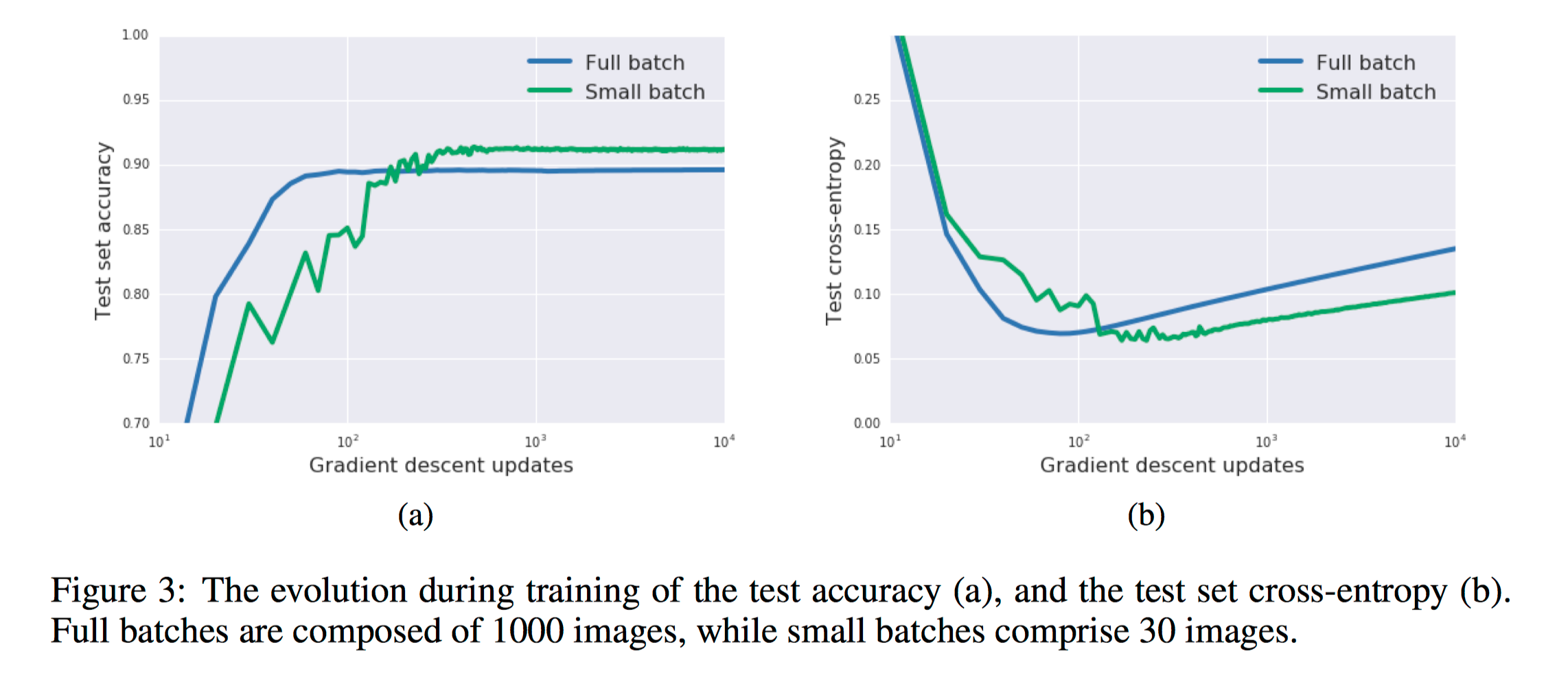
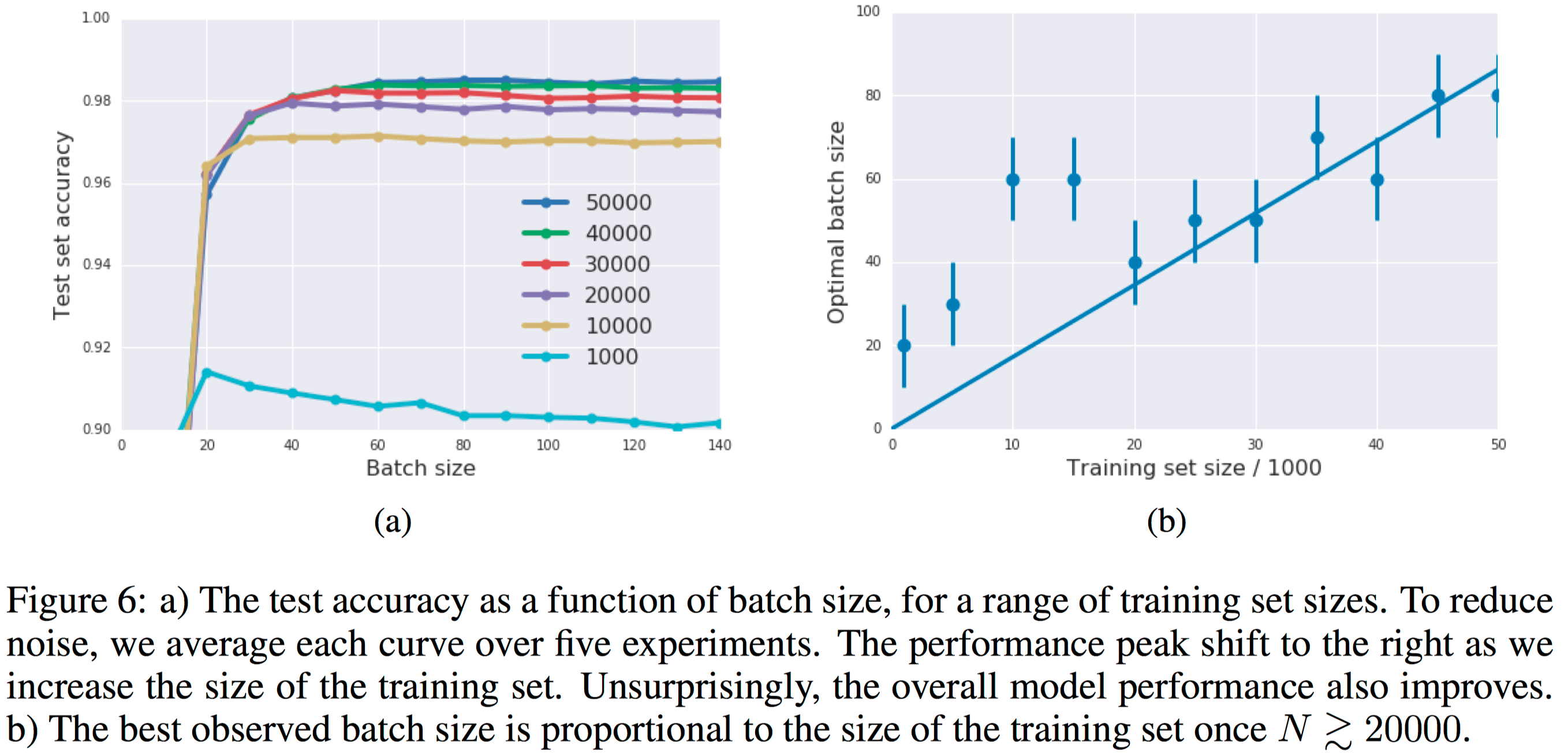
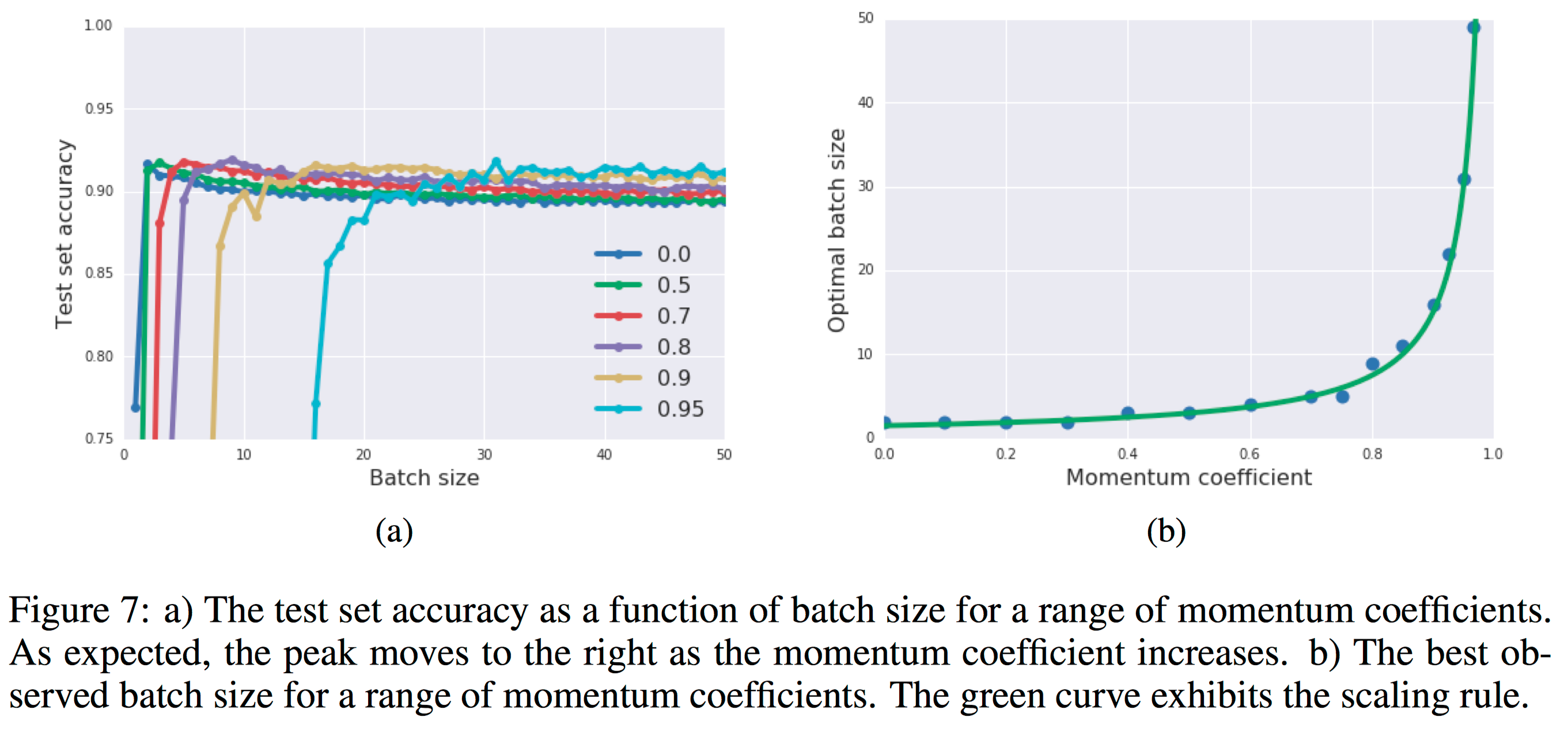
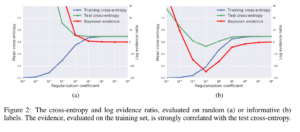
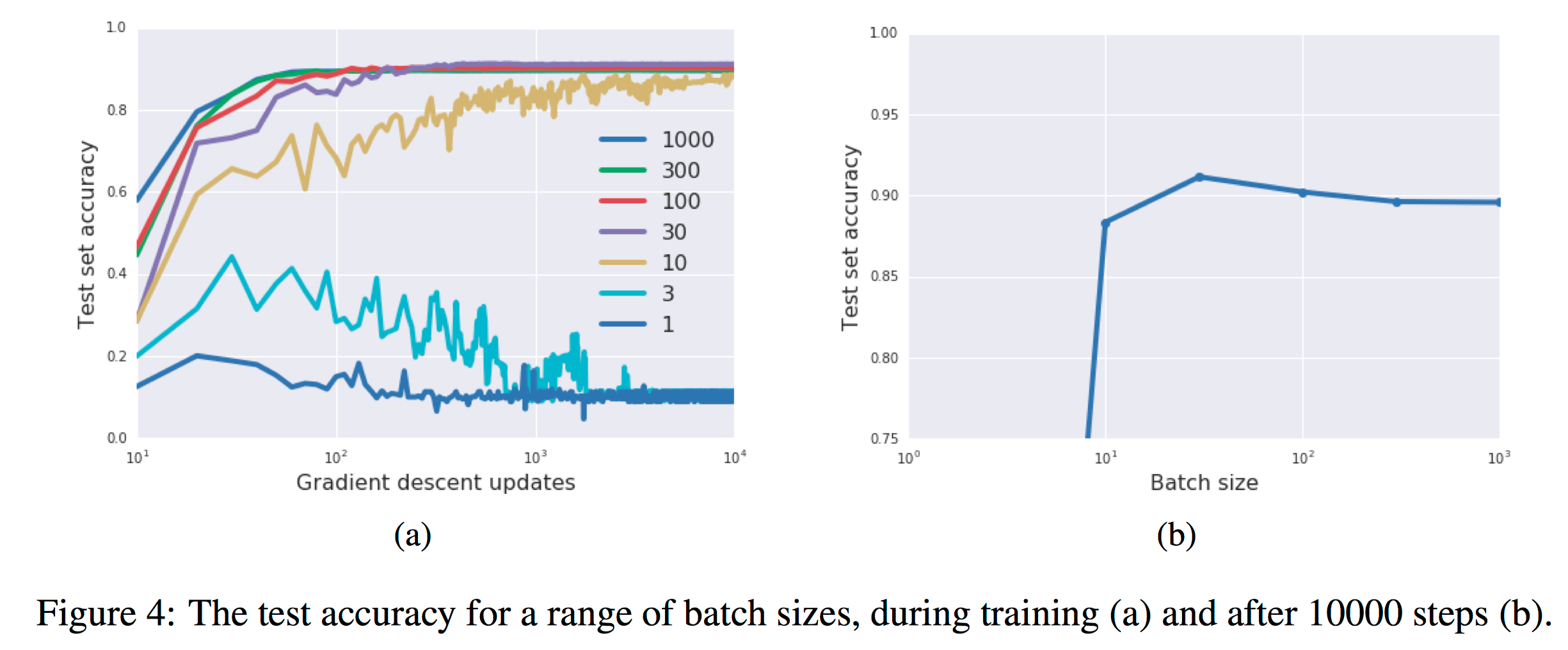 In figure 4a, they exhibit training curves for a range of batch sizes between 1 and 1000. They find that the model cannot train when the batch size B less than 10. In figure 4b they plot the mean test set accuracy after 10000 training steps. A clear peak emerges, indicating that there is indeed an optimum batch size which maximizes the test accuracy, consistent with Bayesian intuition.
In figure 4a, they exhibit training curves for a range of batch sizes between 1 and 1000. They find that the model cannot train when the batch size B less than 10. In figure 4b they plot the mean test set accuracy after 10000 training steps. A clear peak emerges, indicating that there is indeed an optimum batch size which maximizes the test accuracy, consistent with Bayesian intuition.
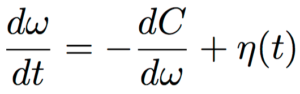

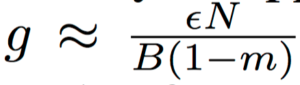









 is the optimization variable and
is the optimization variable and  and
and  for
for 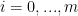 are convex. Both fuction
are convex. Both fuction  and
and  should be affine to make sure DC program is convex.
should be affine to make sure DC program is convex. and
and  are differentiable for the ease of notation. The basic CCP algorithm has the form of gradient desent algorithm with convexify. The procedure is choosing an initial feasible point randomly or through a heuristic if one is known. Then iterates convexity until the stopping criterion is satisfied. in each iteration the
are differentiable for the ease of notation. The basic CCP algorithm has the form of gradient desent algorithm with convexify. The procedure is choosing an initial feasible point randomly or through a heuristic if one is known. Then iterates convexity until the stopping criterion is satisfied. in each iteration the 
 to the solution of the original problem
to the solution of the original problem , where
, where  is threshold. Here as we discussed in the class, the stop criterion can be further improved.
is threshold. Here as we discussed in the class, the stop criterion can be further improved. : replace
: replace  with
with
 for all x, no trust region is needed.
for all x, no trust region is needed. is better than convexified objective
is better than convexified objective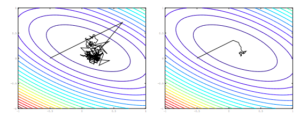
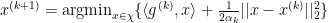
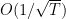
 will be a positive definite matrix such that:
will be a positive definite matrix such that:


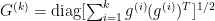
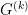 as a diagonal matrix with entries:
as a diagonal matrix with entries: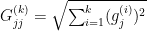
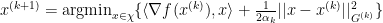

 for all
for all 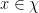
 th partial derivative of the function
th partial derivative of the function  )
) for all
for all 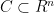
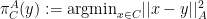
 then:
then: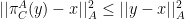
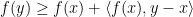
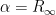 and
and  such that:
such that: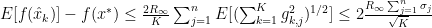

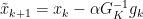
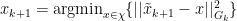
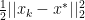
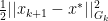


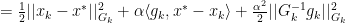
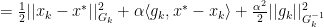
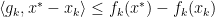
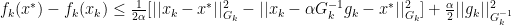
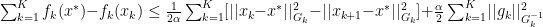
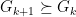 for all
for all 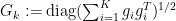 . With this definition we can now create a new Lemma:
. With this definition we can now create a new Lemma:
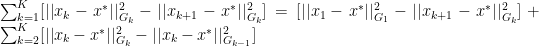
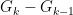 is needed to expand out our summation terms.
is needed to expand out our summation terms.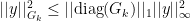
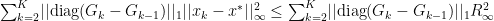

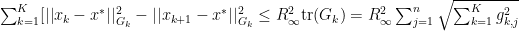
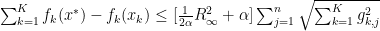
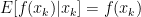 we can now finally modify this to find our convergence proof that we were originally looking for:
we can now finally modify this to find our convergence proof that we were originally looking for: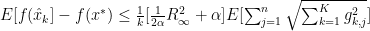
 to
to  are written by Nischel Kandru and rest of them by Ahmadreza Azizi.
are written by Nischel Kandru and rest of them by Ahmadreza Azizi. Consider the Convex Optimization problem which minimizes
Consider the Convex Optimization problem which minimizes  such that
such that 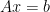 .
.
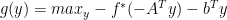 , where
, where 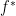 is the convex conjugate of the objective function
is the convex conjugate of the objective function  and
and  is the dual variable or the lagrange multiplier.
is the dual variable or the lagrange multiplier.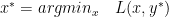
 is the primal optimal point and
is the primal optimal point and 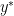 is the dual optimal point; provided there is only one minimizer of
is the dual optimal point; provided there is only one minimizer of  (
(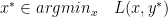
 is differentiable, we find:
is differentiable, we find: and
and 
 : x-minimization step
: x-minimization step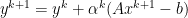 : dual variable update,
: dual variable update, is the iteration step and
is the iteration step and 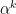 is the step sizes.
is the step sizes.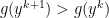 .
. ; maximum over all points
; maximum over all points  evaluated at point
evaluated at point  ; conjugate of conjugate is the function itself. Also,
; conjugate of conjugate is the function itself. Also, 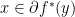 if and only if
if and only if 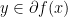 if and only if
if and only if 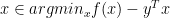 ; if
; if 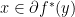 if and only if
if and only if  , sub-gradient for maximum is the one that achieves the maximum. We also know that achieving maximum is same as achieving minimum; so
, sub-gradient for maximum is the one that achieves the maximum. We also know that achieving maximum is same as achieving minimum; so
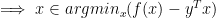
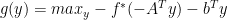 — (1)
— (1)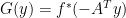
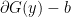 where;
where;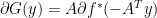
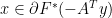 if and only if
if and only if 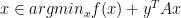
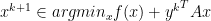
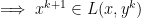
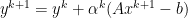
 ,
, 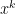 to solutions require strong assumptions
to solutions require strong assumptions


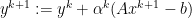
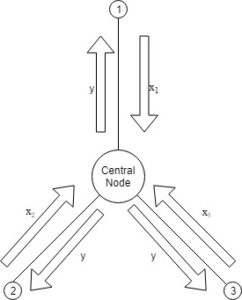

 from each node, update the global dual variable
from each node, update the global dual variable 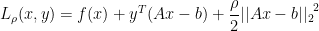
 is the penalty parameter
is the penalty parameter . The new term provides:
. The new term provides: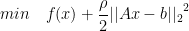
 , dual function
, dual function  can be shown to be differentiable under rather mild conditions on the original problem.
can be shown to be differentiable under rather mild conditions on the original problem.
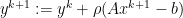
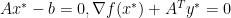
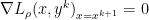 , since
, since 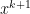 minimizes
minimizes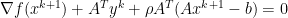
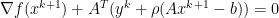
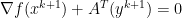
 is dual feasible
is dual feasible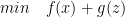

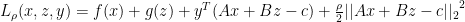
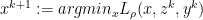 — X- minimization step
— X- minimization step — Z- minimization step
— Z- minimization step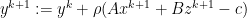 — dual variable update step
— dual variable update step are updated in an alternating fashion.
are updated in an alternating fashion.

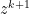 depends on
depends on 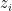 s parallely.
s parallely.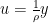 and this makes the computations efficient.
and this makes the computations efficient.