1. Introduction
This blog post covers analysis of Alternating Direction Method of Multipliers (ADMM); which solves Convex Optimization problems by breaking the problems into subproblems efficiently. Sections:  to
to 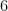 are written by Nischel Kandru and rest of them by Ahmadreza Azizi.
are written by Nischel Kandru and rest of them by Ahmadreza Azizi.
2. Dual Ascent
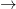 Consider the Convex Optimization problem which minimizes
Consider the Convex Optimization problem which minimizes  such that
such that 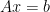 .
.
Lagrangian for this problem is:

Dual problem of the original problem is:
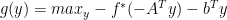 , where
, where 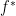 is the convex conjugate of the objective function
is the convex conjugate of the objective function  and
and  is the dual variable or the lagrange multiplier.
is the dual variable or the lagrange multiplier.
If strong duality holds, then the optimal values of the primal and dual problems are the same.
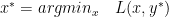
where  is the primal optimal point and
is the primal optimal point and 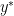 is the dual optimal point; provided there is only one minimizer of
is the dual optimal point; provided there is only one minimizer of  ( is strictly convex)
( is strictly convex)
If is just convex (implies there isn’t a unique minimizer), instead dual-subgradient is performed rather than dual gradient;
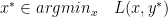
In the dual ascent method, to solve the dual problem, gradient ascent method would be used. Assuming  is differentiable, we find:
is differentiable, we find:
 and
and 
If is non-differentiable, we use sub-gradient method to solve the minimization problem:
 : x-minimization step
: x-minimization step
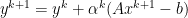 : dual variable update,
: dual variable update,
where  is the iteration step and
is the iteration step and 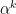 is the step sizes.
is the step sizes.
Repeat the above steps iteratively to solve the optimization problem. This is called dual ascent; because with appropriate step size , we always get 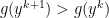 .
.
Let’s derive the above minimization steps:
Given , an objective function then the conjugate of the function:  ; maximum over all points
; maximum over all points  evaluated at point .
evaluated at point .
If is closed and convex, then  ; conjugate of conjugate is the function itself. Also,
; conjugate of conjugate is the function itself. Also, 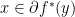 if and only if
if and only if 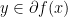 if and only if
if and only if 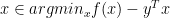 ; if is the subgradient of the conjugate at , if and only if is the subgradient of the original function at .
; if is the subgradient of the conjugate at , if and only if is the subgradient of the original function at .
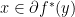 if and only if
if and only if  , sub-gradient for maximum is the one that achieves the maximum. We also know that achieving maximum is same as achieving minimum; so
, sub-gradient for maximum is the one that achieves the maximum. We also know that achieving maximum is same as achieving minimum; so

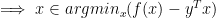
Dual problem:
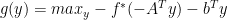 — (1)
— (1)
Suppose 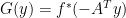
Subgradients of (1) are: 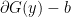 where;
where;
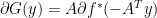
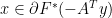 if and only if
if and only if 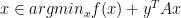
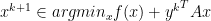
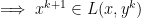
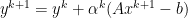
Disadvantages of Dual Ascent
- Slow Convergence
- Even though we may achieve convergence in dual objective value, convergence of
 ,
, 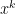 to solutions require strong assumptions
to solutions require strong assumptions
Advantages of Dual Ascent
Decomposability; which leads to Dual Decomposition
3. Dual Decomposition
If is separable, then dual ascent can be decentralized.

The Lagrangian for this problem would be:


we can compute the x-minimization steps in parallel, thanks to the decomposability.
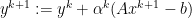
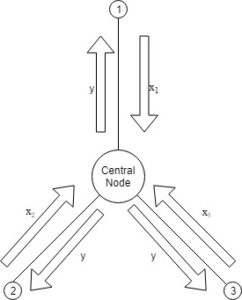
This essentially involves couple of steps:
- Broadcast: Send to each of the other nodes, each optimizes in parallel to find

- Gather: Collect
 from each node, update the global dual variable
from each node, update the global dual variable
4. Augmented Lagrangian and Method of Multipliers
To yield convergence without assumptions like strict convexity, we add a new term; so that the function becomes more convex.
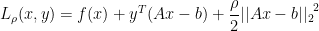
where 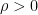 is the penalty parameter
is the penalty parameter
We can clearly see that the addition of the new term doesn’t change the problem as such, because the constraint is 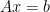 . The new term provides:
. The new term provides:
- Numerical Stability
- Smooths out the primal criterion function
- Introduces curvature into the objective function
Augmented Lagrangian can be viewed as the Lagrangian with problem-
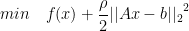
subject to
With the penalty term  , dual function
, dual function  can be shown to be differentiable under rather mild conditions on the original problem.
can be shown to be differentiable under rather mild conditions on the original problem.
Applying dual ascent yields:

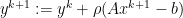
Optimality conditions for original problem are primal and dual feasibility, i.e,
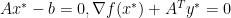
Let’s see the motivation behind having as the stepsize instead of .
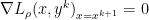 , since
, since 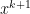 minimizes
minimizes
 is dual feasible
is dual feasible
This is the stationary condition for original problem, so to preserve this use as stepsize.
We get much better convergence in Augmented Lagrangian, but lose out on the decomposability; the solution to this is ADMM which gets the best out of both the worlds.
5. Alternating Direction Method of Multipliers
ADMM combines Decomposability of Dual Ascent and the convergence of Method of Multipliers.
where and are convex, subject to 
The Lagrangian for this problem is:
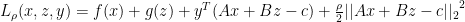
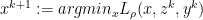 — X- minimization step
— X- minimization step
 — Z- minimization step
— Z- minimization step
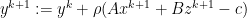 — dual variable update step
— dual variable update step
and  are updated in an alternating fashion.
are updated in an alternating fashion.
We can clearly see that the Z- minimization step depends on the updated value ; so these steps cant be parallelized completely.
The method of multipliers for this problem would have the form:


we can clearly see that, here we try to minimize and together and lose out on the decomposability.
We force decomposability in ADMM, we dont have complete power of decomposability as 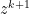 depends on but we can compute all the s and
depends on but we can compute all the s and 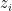 s parallely.
s parallely.
We can see that ADMM doesnt converge as much as the Method of Multipliers and doesnt decompose as much as Dual Decomposition. But, it takes the best of both worlds.
ADMM in general requires lot of iterations for highly accurate solutions, but obtains relatively accurate solution in few iterations.
Scaled Form
We can have a scaled dual variable as: 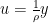 and this makes the computations efficient.
and this makes the computations efficient.

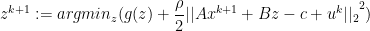

6. References
- http://stanford.edu/~boyd/admm.html
- http://www.stat.cmu.edu/~ryantibs/convexopt-F13/lectures/23-dual-meth.pdf