1.Introduction
The Frank-Wolfe (FW) optimization algorithm has lately regained popularity thanks in particular to its ability to nicely handle the structured constraints appearing in machine learning applications.
In this section, consider the general constrained convex problem of the form:
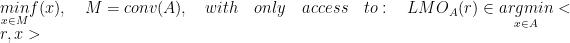
Where 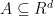
2. Original Frank-Wolfe algorithm
The Frank-Wolfe (FW) optimization algorithm, also known as conditional gradient, is particularly suited for the setup. It works as follows:
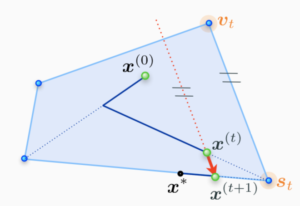
At a current iterate x^(t), the algorithm finds a feasible search atom st to move towards by minimizing the linearization of the objective function f over M – this is where the linear minimization oracle LMOa is used.
The next iterate x^(t+1) is then obtained by doing a line-search on f between x^(t) and st.

3. Variants of Frank-Wolfe algorithm
3.1 Away-Frank-Wolfe Algorithm
However, there is zig-zagging phenomenon. In order to address this phenomenon, away-Frank-Wolfe algorithm is proposed. Add the possibility to move away from an active atom in 

3.2 Pairwise Frank-Wolfe Algorithm
pairwise Frank-Wolfe algorithm is also called MDM algorithm. At first, it proposed to address the polytope distance problem. It hopes to move weight mass between two atoms in each step. According to the algorithm 3, we can know that is almost algorithm 2, except 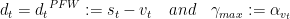

4. Global Linear Convergence Analysis
In this paper, section 2 is talking about global linear convergence analysis. We can see that at first, it introduce the proof elements and convergence proof. And lately, section 2.2 is talking convergence results.
4.1 proof of convergence
4.1.1
As f has the L-Lipschitz gradient, we can get
![f({ x }^{ (t+1) })\le f({ x }^{ (t) })+\gamma <\nabla f({ x }^{ (t) },{ d }_{ t })>+\frac { { \gamma }^{ 2 } }{ 2 } L{ ||{ d }_{ t }|| }^{ 2 }\quad \quad \forall \gamma \in [0,{ \gamma }_{ max }]](https://s0.wp.com/latex.php?latex=f%28%7B+x+%7D%5E%7B+%28t%2B1%29+%7D%29%5Cle+f%28%7B+x+%7D%5E%7B+%28t%29+%7D%29%2B%5Cgamma+%3C%5Cnabla+f%28%7B+x+%7D%5E%7B+%28t%29+%7D%2C%7B+d+%7D_%7B+t+%7D%29%3E%2B%5Cfrac+%7B+%7B+%5Cgamma+%7D%5E%7B+2+%7D+%7D%7B+2+%7D+L%7B+%7C%7C%7B+d+%7D_%7B+t+%7D%7C%7C+%7D%5E%7B+2+%7D%5Cquad+%5Cquad+%5Cforall+%5Cgamma+%5Cin+%5B0%2C%7B+%5Cgamma+%7D_%7B+max+%7D%5D&bg=ffffff&fg=000&s=0&c=20201002)
Choose 
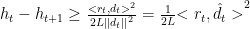
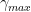
4.1.2
By 

![f({ x }^{ (t) }+\gamma { e }_{ t })\ge f({ x }^{ (t) })+\gamma <\nabla f({ x }^{ (t) },{ e }_{ t })>+\frac { { \gamma }^{ 2 } }{ 2 } \mu { ||{ e }_{ t }|| }^{ 2 }\quad \forall \gamma \in [0,1]](https://s0.wp.com/latex.php?latex=f%28%7B+x+%7D%5E%7B+%28t%29+%7D%2B%5Cgamma+%7B+e+%7D_%7B+t+%7D%29%5Cge+f%28%7B+x+%7D%5E%7B+%28t%29+%7D%29%2B%5Cgamma+%3C%5Cnabla+f%28%7B+x+%7D%5E%7B+%28t%29+%7D%2C%7B+e+%7D_%7B+t+%7D%29%3E%2B%5Cfrac+%7B+%7B+%5Cgamma+%7D%5E%7B+2+%7D+%7D%7B+2+%7D+%5Cmu+%7B+%7C%7C%7B+e+%7D_%7B+t+%7D%7C%7C+%7D%5E%7B+2+%7D%5Cquad+%5Cforall+%5Cgamma+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Use

4.1.3
combining 4.1.1 and 4.1.2, we can get
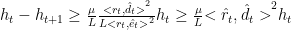
Thus, lower bounds * to get linear convergence rate.
5. Conclusion
This paper reviews variant of FW algorithm and shows for the first time global linear convergence for all variants of FW algorithm. It introduces of the notion of the condition number of the constraint set.
6. Reference
1. Simon Lacoste- Julien & Martin Jaggi: On the global linear convergence of Frank-Wolfe optimization variants.
2. Simon Lacoste- Julien & Martin Jaggi: http://www.m8j.net/math/poster-NIPS2015-AFW.pdf
3. R. Denhardt-Eriksson & F. Statti: http://transp-or.epfl.ch/zinal/2018/slides/FWvariants.pdf