AdaGrad is simply just an optimization method based off of the Proximal Point Algorithm (otherwise known as the Gradient Descent algorithm), specifically the Stochastic version of gradient descent. The intention behind the formulation of AdaGrad is because SGD (stochastic gradient descent) converges slowly in the cases when features of our model are significantly more important than others. This is because the original SGD algorithm treats all factors equally, regardless of how much each factor contributes towards the actual models outputs.
Seen below, we can recognize that the stochastic gradient descent algorithm takes a large amount of time in order to find the optimal solution because of the constant jumping back and forth on the expected gradient (seen Left). On the otherhand, if we were to average all of the iterates in SGD (not AdaGrad), we can find a much quicker optimization and decrease the amount of backtracking done.
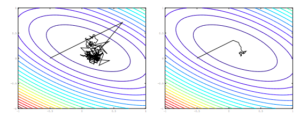
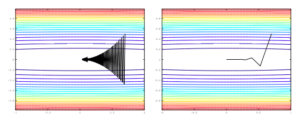
Now consider a case where we have an extremely wide problem domain, most likely due to a feature having an exaggerated effect on the domain. Seen below, we can see that the standard proximal gradient method (SGD) ends up jumping back and forth because it is a poorly conditioned problem. On the other hand, we can see the AdaGrad variant (which somewhat fixes the poor conditioning of the problem) will end up getting to the optimal in a significantly smaller number of steps.
The original SGD algorithm’s update method defines the update rule as:
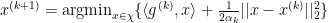
This version of the algorithm has a general convergence rate of
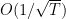
AdaGrad takes advantage of the matrix norm, in our case, 

This matrix $B$ has a list of diagonal terms that will modify the update rule of SGD such that:

which is equivalent to an update rule of:

As can be seen when compared to the original update rule, we have introduced the diagonal matrix
AdaGrad now extends the SGD algorithm by defining within iteration 
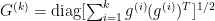
We can define 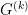
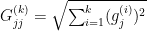
Therefore modifying our previous modified update rule to be our final update rule for Adagrad:
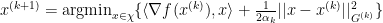
which is equivalent to an update rule of:

Proof of Convergence:
In order to go about proving that this new update rule will converge on the optimal solution just as SGD does, we must go about looking at the logic behind our choosing the diagonal matrix for our value of the matrix $B$.
To go about proving this we must have a couple of initial assumptions, definitions, and observations:
Assumption 1

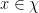
Definition 1
(bound on the second moments of the 


Observation 1
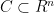
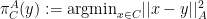
for any 
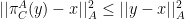
Observation 2

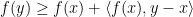
We utilize a theorem defined in the original paper which is also proved later on in the paper that suggests that given a step-size 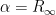

Theorem 3
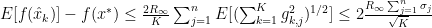
The above equation is what we want to end up proving in order to show that the AdaGrad algorithm will converge on an optimal solution given enough steps
Proof
Now that we’ve gone about and defined all of our required values, we can go about proving the convergence of the AdaGrad algorithm.
We first look at our update step of:

which when projected into our problem space:
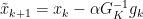
such that our new update step can be:
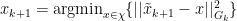
This can be seen that the Potential Function is:
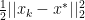
And the AdaGrad Function would then be:
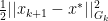
Here, we’ll modify our AdaGrad function utilizing the previous definitions and the Potential function:


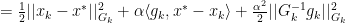
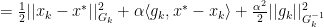
We can see that the middle term of the final equation can be seen as:
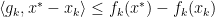
This rightmost term can be modfied to be:
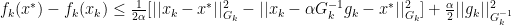
We can now modify this step with a summation of elements such that:
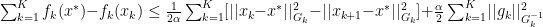
With this step, we can define 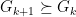
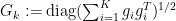

Since we’ve expanded out our summation of elements above, we need to reduce our first term on the right side of the $\leq$ sign:
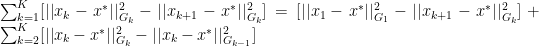
The final term in the above equation is based off of the definitions of the norm and applying out when 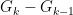
We use the basic definition of our space and the diagonal to form the defintion:
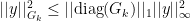
We use this definition in the final term of the previous equation that was expanded out in order to see that:
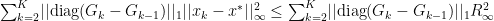
For better understanding we will define a new function:

Using the Assumption 1 we can now see that:
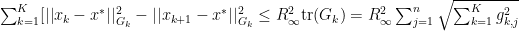
Going back to one of our previous definitions, we can reduce this to:
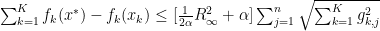
Given the fact that the potential function 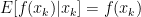
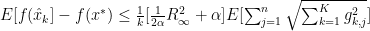
This proves that our given new update rule for AdaGrad will produce an optimal solution at (approximately) the same rate that SGD does.