In machine learning (supervised learning), we train a model by minimizing a loss function that outputs the difference between our prediction given a data point and the true label of that data point. Learning is cast as an optimization problem and often we use gradient descent or its variants to seek solution to this problem.
In the previous post we learnt about Gradient Descent, Newton’s method and LBFGS optimization techniques. In this post we will cover natural gradient, its formulation, usage and applications in machine learning.
To understand natural gradient, we need to revise our understanding of distance. We define the distance between two points 
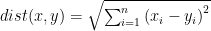
This distance measure is not appropriate if our function of interest lies in a different geometric space other than the Euclidean space. Natural gradient employs this property by giving the distance between two points
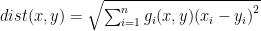
where 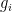
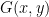
The Riemannian metric tensor that is used in natural gradient formulation is the Fisher information matrix
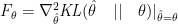
Fisher information matrix is the second derivative of the KL-divergence. For anyone familiar with statistics, KL-divergence is a measure to determine how close a probability distribution is from another probability distribution.
Putting it all together, recall for the optimization problem 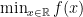
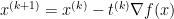
For natural gradient, we update the parameters of our function using
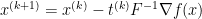
where 

Now that we have learnt what natural gradient is and how it is formulated, we ask the question why isn’t this method popular in machine learning and what problems are they good for solving? In practice, natural gradient method is applied to a variety of problems, variational inference, deep neural networks, reinforcement learning and in some cases it performs better than conventional methods e.g. stochastic gradient descent. The main limitation of natural gradient method is that we need to know the Riemannian structure of the parameter space of our function in order to derive its update rule and deriving the algorithm for that can be complex. Also, applying the algorithm can be computationally intensive.
In this post, we have learnt about natural gradient and that it performs better than conventional optimization methods when applied to some problems. I will strongly encourage anyone seeking a more in depth coverage of natural gradient adaptation to check out this paper, or alternatively, this paper to get a concise explanation with mathematical derivations.