In the first few sessions of the course, we went over gradient descent (with exact line search), Newton’s Method, and quasi-Newton methods. For me, and many of the students, this was the first time I had sat down to go over the convergence guarantees of these methods and how they are proven.
Generally, we were examining descent methods that aim to solve optimizations of the form
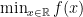
by iteratively trying input vectors in a sequence defined by
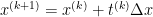
For the analyses we studied so far, we assume the function is strongly convex, meaning that there exists some constant 
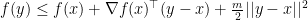
and there is another constant 
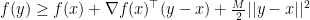
In other words, the function can be upper and lower bounded by quadratic functions.
Gradient Descent
We first went over the proof in Boyd and Vanderberghe’s textbook on convex optimization for gradient descent. The approach they used to show the convergence rate of gradient descent was to bound the improvement each iteration, which shows that the gap between the current objective value and the optimal objective value shrinks by a constant factor each iteration. This constant factor shrinkage is known as linear convergence. This type of analysis results in a bound of the form
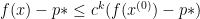
where 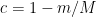
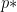

Newton’s Method
We continued with the Boyd & Vanderberghe book, looking at its discussion of Newton’s Method (with backtracking). Many of us in the class had the rough idea that Newton’s Method, because it uses second-order information, achieves a quadratic convergence rate, and the analysis does confirm that.
The backtracking Newton Update is

where the step size $t^{(k)}$ shrinks until [to-do: describe backtracking condition].
The analysis adds another assumption about
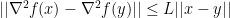
The convergence analysis is broken into two phases, one where the backtracking search backtracks, and the other where the full Newton Step is used. During the phase with the full Newton Step, it is shown that the error is bounded by a rapidly shrinking constant:
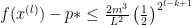
where 
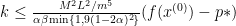
In this formula 
LBFGS
Newton’s Method is great, but each iteration is rather expensive because it involves the computation of the Hessian and inverting it. For high-dimensional problems, this can make Newton’s Method practically unusable. Our last topic of this block of classes was on one of the more famous quasi-Newton methods. We decided to read the highly cite paper [to-do paper title], but we were surprised as a class to discover that this paper is more of an empirical study of LBFGS in comparison to other quasi-Newton approaches. So we supplemented with other resources, like Vandenberghe’s slides.
We were surprised in the proof presented in Liu and Nocedal’s paper that they prove LBFGS to be a linearly converging method. If LBFGS is not provably faster than gradient descent, it’s not clear why anyone would use it. However, we hypothesized as a class that there may be other proofs elsewhere that show super-linear convergence, because many of us thought we had seen LBFGS listed as a super-linear algorithm. We’ll certainly look into this later as a class.
We spent time in class going over the secant condition that LBFGS, and BFGS, uses to approximate the Hessian. The key idea we had to understand is that the secant method can be viewed as a linear approximation of the Hessian analogous to making a linear approximation of the gradient by measuring the function value at two points. One measures the gradient at two locations 
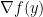

The BFGS method then iteratively projects the previous Hessian approximation onto the space of Hessian approximations that agree with this condition, which is reasonable if you believe the Hessian does not change much. LBFGS instead only stores the previous
We also puzzled over how LBFGS can avoid the quadratic cost of either storing or computing the approximate Hessian. As a class, we were initially confused because most formulas for the approximate Hessian include outer product terms involving the differences between the input vectors and the gradients, e.g.,
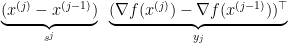
where 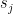

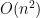
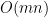
The key insight to why we can avoid the quadratic cost—of even thinking about the full-sized Hessian—is that in all cases of these outer products, they are eventually right multiplied by yet another vector of length 

which can be computed much more efficiently by first multiplying the dot product on the right:
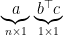
Concluding Thoughts
One of my goals with looking at these foundational methods first was to gain an intuition of how to prove convergence of more sophisticated optimization approaches. To do so, I was hoping to find nice patterns of proof techniques. I’m not certain that I did that, personally, with these three analyses. Parts of the analyses were analogous to each other, but overall, their convergence proofs seemed rather different to me. Perhaps as we see more analyses throughout the semester, we’ll start to recognize patterns more.
It’s interesting to have sat down to really dig into these methods, since so much of what I know as a machine learning researchers comes from “mythology” about these methods. One important note is the strength of the assumptions underlying the convergence guarantees. We often use these methods and variants on functions that may not be strongly convex or convex at all. These misuses of these algorithms will naturally occur. “When all you have is a hammer…” From spending three (and a half) classes looking at these convergence guarantees, I don’t yet have a clear idea of what we can say theoretically when these assumptions are violated.