Paper:
Walter S. Lasecki, Mitchell Gordon, Winnie Leung, Ellen Lim, Jeffrey P. Bigham, and Steven P. Dow. 2015. Exploring Privacy and Accuracy Trade-Offs in Crowdsourced Behavioral Video Coding. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (CHI ’15). ACM, New York, NY, USA, 1945-1954. DOI: https://doi.org/10.1145/2702123.2702605
Discussion Leader: Sukrit V
Summary:
Social science and interaction researches often need to review video data to learn more about human behavior and interaction. However, computer vision is still not advanced enough to automatically detect human behavior. Thus, video data is still mostly manually coded. This is a terribly time-intensive process and often takes up to ten times the length of a video to code it.
Recent work in the crowdsourcing space has been successful in using crowds to code for behavioral cues. This method, albeit much faster, introduces other concerns.
The paper provides a brief background of how video data is typically coded and current research in the space of video annotation using crowds. The authors interviewed twelve practitioners who have each coded at least 100 hours of video to obtain a better understanding of current video coding practices and what they believe are the potential benefits and concerns of utilizing crowdsourcing in a behavioral video coding process. From the interviews, they deduced that video coding is a time-consuming process and is used in a wide variety of contexts and to code for a range of behaviors. Even developing a coding schema is difficult due to inter-rater agreement requirements. The researchers were open to the idea of using online crowds as part of the video coding service, but they had concerns with the quality and reliability of the crowds, in addition to maintaining participant privacy and meeting IRB requirements.
The paper details an experimental study to explore the ability and accuracy of crowds to code for a range of behavior, and how obfuscation methods would affect a worker’s ability to identify participant behavior and identity. From the first experiment, they were able to obtain relatively high precision and recall rates for coding a range of behaviors, except for smiling and head turning. This was attributed to a lack of clarity on the instructions and example provided for those two. In the second experiment, they varied the blur level of the videos and observed that the decay rate in personally identifiable information dropped more steeply than the F1 rates did. This means that, it is easier to preserve privacy at higher blur levels and still maintain relatively good levels of precision and recall.
The authors also created a tool, Incognito, for researches to test what level of privacy protection filters are sufficient for their use case and what impact it would have on the accuracy of the crowdsourced coding. They conclude with a discussion of future work: utilizing different approaches to filtering, and performing real-world usage studies.
Reflection:
The paper is rather well organized, and the experiments were quite straightforward and well-detailed. The graphs and images present were sufficient.
I quite liked the ‘lineup tool’ that they utilized at the end of each video coding task and mimicked what is used in real life. In addition, their side-experiment to determine whether the workers were better at identifying participants if they were prompted beforehand, is something that I believe is useful to know and could be applied in other types of experiments.
I believe the tool they designed, Incognito, would prove extremely useful for researchers since it abstracts the process of obfuscating the video and hiring workers on MTurk. However, it would have been nice if the paper mentioned what instructions the MTurk workers were given on coding the videos. In addition, perhaps training these workers using a tutorial may have produced better results. Also, they noted that coding done by experts is a time-consuming process and the time taken to do so linearly correlates with the size of the dataset. Something that would be interesting to study is how the accuracy of coding done by the crowd-sourced workers would change with increased practice over time. This may further reduce the overhead of the experts, provided that coding standards are maintained.
Furthermore, the authors mention the crowdsourced workers’ precision and recall rates, but it would be nice if they had looked into the inter-rater agreement rates as well since that plays a vital role in video coding.
For coding smiles they used an unobfuscated window of the mouth, and the entire study focuses on blurring the whole image to preserve privacy. I wish they had considered – or even mentioned – using facial recognition algorithms to blur only the faces (which I believe would still preserve privacy to a very high degree), yet greatly increase the accuracy when it comes to coding other behaviors.
Overall, this is a very detailed, exploratory paper in determining the privacy-accuracy tradeoffs when utilizing crowdsourced workers to perform video coding.
Questions:
- The authors noted that there was no change in precision and recall at blur levels 3 and 10 when the workers were notified that they were going to be asked to identify participants after their task. That is, even when they were informed beforehand about having to perform a line-up test, they were no better or worse at recognizing the person’s face (“accessing and recalling this information”). Why do you think there was no change?
- Can you think of cases where using crowdsourced workers would not be appropriate for coding video?
- The aim of this paper was to protect the privacy of participants in the videos that needed to be coded, and was concerned with their identity being discovered/disclosed by crowdsourced workers. How important is it for these people’s identities to be protected when it is the experts themselves (or for example, some governmental entities) that are performing the coding?
- How do you think the crowdsourced workers compare to experts with regards to coding accuracy? Perhaps it would be better to have a hierarchy where these workers code the videos and, below a certain threshold level of agreement between the workers, the experts would intervene and code the videos themselves. Would this be too complicated? How would you evaluate such a system for inter-rater agreement?
- Can you think of other approaches – apart from facial recognition with blurring, and blurring the whole image – that can be used to preserve privacy yet utilize the parallelism of the crowd?
- Aside: How do precision and recall relate to Cohen’s kappa?


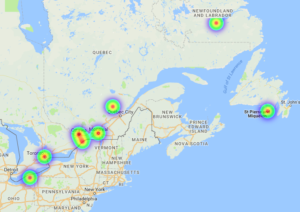 either link. Let’s look at the HeatMap first. The slide bar is to adjust display thresholds. If we zoom in, we can see protests occurred in Southern Ontario, Toronto, Ottawa, Montreal, outside Quebec City and even some in Newfoundland and Labrador.
either link. Let’s look at the HeatMap first. The slide bar is to adjust display thresholds. If we zoom in, we can see protests occurred in Southern Ontario, Toronto, Ottawa, Montreal, outside Quebec City and even some in Newfoundland and Labrador.