Rev. Ray Broshear and his band of 21 homosexuals, cleverly named the Lavender Panthers, patrolled the streets of San Francisco nightly in the early 1970s with chains, batons, and an extensive knowledge of martial arts to protect others in their community from further injustices. Their “flailing ass” approach is just one response of many to when the judicial system fails. Like the Lavender Panthers, when justice is foreclosed, people might resort to self-help, or measures external to the judicial system, such as expressions of disapproval, beatings, and riots [1].
Much has changed since the days of the Lavender Panthers. Beyond a shifting social context, the source of judicial error is gradually becoming increasingly algorithmic. Many facets of the judicial system incorporate predictive risk assessments into their decision-making processes, which classify offenders into risk levels for recidivism. Nominally, the resultant scores counteract some of the errors made by humans [2, 3]. Withal these predictions have their own problems [4-7]. If past human judicial injustices lead people to self-help, will algorithmic injustices similarly motivate the Ray Brashears and Lavender Panthers of the 21st century?
Most likely not, rather it might actually motivate them even more. Psychology and human-computer interaction literature finds that people express preference for human rather than algorithmic forecasting after errors have occurred [8-12]. This preference holds up even when the human forecaster produced 90-97% more errors than the algorithmic forecaster [9]. But will this algorithm aversion apply to the criminal justice system? And, will people exposed to algorithmic-error circumvent the system even more than when faced with human-error?
To answer these questions, I turned to MTurk and randomly assigned 701 respondents into two groups before asking them to read a scenario of low-risk offenders committing more crime after being released into the community. The only difference between the groups was the decision source: either an algorithm or human forecaster. Everyone then indicated their support for extrajudicial activities (see figures 1-3) as well as their attitudes towards the judicial system.
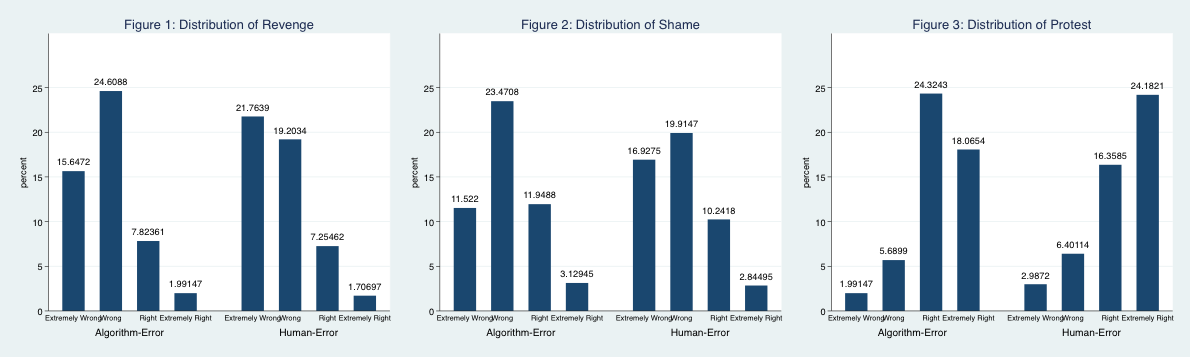
The findings suggest that the source of judicial error does matter. People that read the algorithm error scenario had greater odds of believing revenge and naming and shaming was extremely right. The opposite held true for protesting laws or policies that you think are unjust.
At first glance, it appears that people bypass the system only some of the time. However, if we take a closer look at the motivations behind the self-help behaviors it is possible that people support circumventing the system more often when algorithmic-error is involved.
Remember the Lavender Panthers. They did not see the usefulness of protesting an unwilling system. Instead, physical violence was their approach. People protest when they believe the system can still be changed. They must believe that their actions can influence wider social structures [13, 14]. In contrast, picking up a baton or chain and hitting the streets to “flail ass” does not. Coupled with this efficacy argument, people in the algorithm group could hold the erroneous assumption that algorithms cannot learn from past mistakes [9, 15, 16]. If people hold this belief, then protesting becomes even less efficacious. In other words, why protest to a system that cannot change?
To answer the previous questions, yes and yes. Algorithm aversion does apply to the judicial system. And, yes people exposed to algorithmic-error want to circumvent the system more than when the system appears inaccessible. These findings become concerning with more and more algorithms being used within the system each year, which increases the potential for judicial error from an algorithm that could lead to greater levels of revenge and protest.
References
1 ‘The Sexes: The Lavender Panthers’, in Editor (Ed.)^(Eds.): ‘Book The Sexes: The Lavender Panthers’ (1973, edn.), pp.
2 Baird, C., Healy, T., Johnson, K., Bogie, A., Dankert, E.W., and Scharenbroch, C.: ‘A comparison of risk assessment instruments in juvenile justice’, Madison, WI: National Council on Crime and Delinquency, 2013
3 Berk, R.: ‘Criminal justice forecasts of risk: A machine learning approach’ (Springer Science & Business Media, 2012. 2012)
4 Starr, S.B.: ‘The New Profiling’, Federal Sentencing Reporter, 2015, 27, (4), pp. 229-236
5 O’Neil, C.: ‘Weapons of math destruction: How big data increases inequality and threatens democracy’ (Broadway Books, 2017. 2017)
6 Johndrow, J.E., and Lum, K.: ‘An algorithm for removing sensitive information: application to race-independent recidivism prediction’, arXiv preprint arXiv:1703.04957, 2017
7 Angwin, J., Larson, J., Mattu, S., and Kirchner, L.: ‘Machine bias: There’s software used across the country to predict future criminals. and it’s biased against blacks’, ProPublica, May, 2016, 23
8 Dietvorst, B.J., Simmons, J.P., and Massey, C.: ‘Overcoming Algorithm Aversion: People Will Use Imperfect Algorithms If They Can (Even Slightly) Modify Them’, Management Science, 2016
9 Dietvorst, B.J., Simmons, J.P., and Massey, C.: ‘Algorithm aversion: People erroneously avoid algorithms after seeing them err’, Journal of Experimental Psychology: General, 2015, 144, (1), pp. 114
10 Dzindolet, M.T., Pierce, L.G., Beck, H.P., and Dawe, L.A.: ‘The perceived utility of human and automated aids in a visual detection task’, Human Factors, 2002, 44, (1), pp. 79-94
11 Önkal, D., Goodwin, P., Thomson, M., Gönül, S., and Pollock, A.: ‘The relative influence of advice from human experts and statistical methods on forecast adjustments’, Journal of Behavioral Decision Making, 2009, 22, (4), pp. 390-409
12 Prahl, A., and Van Swol, L.: ‘Understanding algorithm aversion: When is advice from automation discounted?’, Journal of Forecasting, 2017
13 Van Stekelenburg, J., and Klandermans, B.: ‘The social psychology of protest’, Current Sociology, 2013, 61, (5-6), pp. 886-905
14 Gamson, W.A.: ‘Talking politics’ (Cambridge university press, 1992. 1992)
15 Highhouse, S.: ‘Stubborn reliance on intuition and subjectivity in employee selection’, Industrial and Organizational Psychology, 2008, 1, (3), pp. 333-342
16 Dawes, R.M.: ‘The robust beauty of improper linear models in decision making’, American psychologist, 1979, 34, (7), pp. 571
Read More