We define standard gradient descent as:
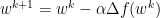
Momentum adds a relatively subtle change to gradient descent by replace f with z. Where
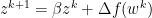
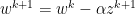
As such, alpha retains the role of representing the step size. However, we introduce a new constant, beta. Beta adds a decaying effect on momentum, and must be between 0 and 1, noninclusive. We briefly demonstrate the edge cases of beta below:
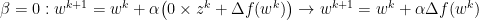
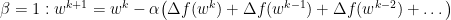
We now introduce a change of basis which will be convenient for later. Consider a matrix form of gradient descent:
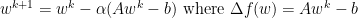
Which has optimal solution
we consider the eigenvectors of A which is a natural space of viewing A where all dimensions act independently.
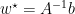
Given:
$latex A = Q \text{ diag }(\lambda_1 \dots \lambda_n)Q^T $
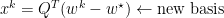
We may derive this by:
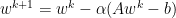
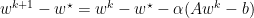
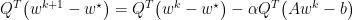
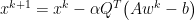
$latex = \sum_i^n x_i^0(1-\alpha \lambda_i)^k q_i $

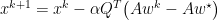

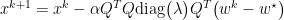

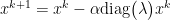
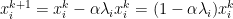
Thus, we now can view gradient descent in basis of the eigenvectors of A. We consider the contributions of error as
$latex f(w^k)-f(w^\star) = \sum (1 – \alpha \lambda_i)^{2k} \lambda_i [x_i^0]^2 $
For convergence, we note that
$latex 1 – \alpha \lambda_i $
must be strictly less than 1.
Note: To be continued…