Introduction
Proximal algorithms are a class of algorithms that can be used to solve constrained optimization problems that may involve non-smooth penalties in the objective function. Their formulation is rather general in that a number of other optimization algorithms can be derived as special cases of proximal algorithms. At the core of proximal algorithms exists the evaluation of the proximal operator:

The proximal operator returns a point in the search space that minimizes the problem defined by the Moreau envelope of the objective function 

The Moreau envelope is a regularized version of the function 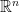
Example 1. Let 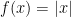



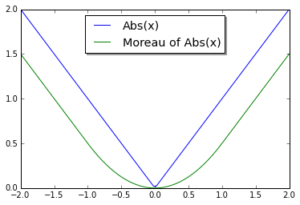
Notice that the Moreau envelope is smooth even though
Standard Problem Formulation
Consider the minimization of functions of the form
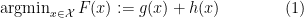
where 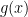
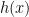
Gradient descent can be used to minimize the original objective 



When the solution to the proximal operator of
Proximal Gradient Descent Method
Proximal gradient descent method can be employed to solve optimization problems of type (1). It is composed of the following two steps:
- Gradient step: Starting at
, take a step in the direction of the gradient of the differentiable part,
- Evaluate prox operator: Starting at
, evaluate the prox operator of the non-smooth part,


In [2], the authors give a glimpse into how the above recipe can be motivated in two different ways — first as an MM-algorithm and second by deriving optimality conditions using subdifferential calculus.
Proximal Gradient Descent method will require
Proximal Newton Method
In Proximal Gradient Descent Method, the gradient step is obtained by constructing a quadratic under-approximant to the differentiable function using the scaled identity, 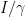
Proximal Newton Method can be obtained by using the actual Hessian, 


where 
- Newton step: Starting at
- Evaluate prox operator: Starting at
- Take a step in direction
: Starting at
as:



It should be noted that the the proximal operator in the case of Proximal Newton Method relies on the computation of the Hessian. Hence, any line search strategy to identify an appropriate step size will prove expensive.
Proximal Gradient Descent Method can be recovered from Proximal Newton Method by replacing the Hessian with 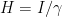
Nesterov Acceleration
Nesterov suggests that the optimal convergence rate for first order methods is 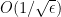
- Choose initial point:
- Compute an intermediate vector
: Starting at
and
, evaluate:
- Evaluate the prox operator after taking a gradient step using
as:



The intepretation of
is the same as momentum. If 
Summary
Proximal algorithms can be used to solve constrained optimization problems that can be split into sum of convex differentiable and convex non-smooth parts. If the prox operator is cheap to evaluate, then linear convergence is recovered in the usual scenario, like in the case of gradient descent. Several other algorithms can be recast in terms of a proximal method [1,2]. Although closed form solutions to prox operator may be required, in [7] the authors study the convergence rates when the prox operator is evaluated in an inexact manner.
References
[1] Parikh, N. and Boyd, S., 2014. Proximal algorithms. Foundations and Trends® in Optimization, 1(3), pp.127-239. [paper]
[2] Polson, N.G., Scott, J.G. and Willard, B.T., 2015. Proximal algorithms in statistics and machine learning. Statistical Science, 30(4), pp.559-581. [paper]
[3] Boyd, S., Xiao, L. and Mutapcic, A., 2003. Subgradient methods. lecture notes of EE392o, Stanford University, Autumn Quarter, 2004, pp.2004-2005. [monograph]
[4] Tibshirani, R., 2016. Proximal Newton Method. Slides from 10-725, Carnegie Mellon University, Fall , 2016. [presentation]
[5] Nesterov, Y., 1983, February. A method of solving a convex programming problem with convergence rate O (1/k2). In Soviet Mathematics Doklady (Vol. 27, No. 2, pp. 372-376). [paper]
[6] Nesterov, Y., 2013. Introductory lectures on convex optimization: A basic course (Vol. 87). Springer Science & Business Media. [book]
[7] Schmidt, M., Roux, N.L. and Bach, F.R., 2011. Convergence rates of inexact proximal-gradient methods for convex optimization. In Advances in neural information processing systems (pp. 1458-1466). [paper]