This paper is about decoding real world people interaction using thought experiments and gaming scenarios. A game of diplomacy with its interactions provides a perfect opportunity to learn about changes in player communucations with relation to oncoming betrayal.
Can the betrayal really be automatically predicted by tonal change in communication ? Is it generalizable to other real world scenario or even artificial scenario like other games ?
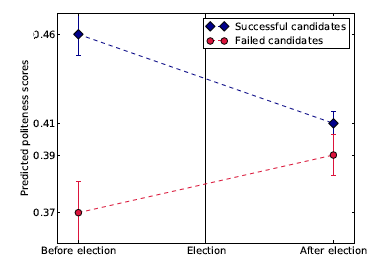
The paper shows that the game supports long term alliances but it offers lucrative solo victories too, leading to betrayals. Alliances get broken with time which is intuitive. The paper provided defined structures for defining friendship, betrayal and the parties involved, victim and betrayer through the communications as well as the game commands. The structure of the discourse provides enough linguistic clues to determine whether friendship will last or not for a considerable period of time. The authors also develop a logistic regression to create a model for predicting betrayal. Few questions which arise are : are linguistic cues general enough because people talk differently even in a strict English speaking nation. Similar question for betrayal : the betrayer are usually more polite before the act . It could be in context of this game and may or may not apply elsewhere, even in other games.
The paper makes a point of sudden yet inevitable betrayal where more markers are provided by the victim than the betrayer. The victim uses more planning words and is less polite than usual. In context of this game, long term planning is a measure of trust, so can it be generalized to more trust results in inevitable betrayal conclusion ? It could be far-fetched even with many anecdotal evidences.
Lastly, I believe the premise is highly unrealistic and not at all comparable to real world scenarios. Also, the proposition that betrayal can be predicted is highly doubtful and cannot be relied upon for real world communications. Also, since it is based on linguistic evaluations, this system can be gamed making the point of prediction useless.