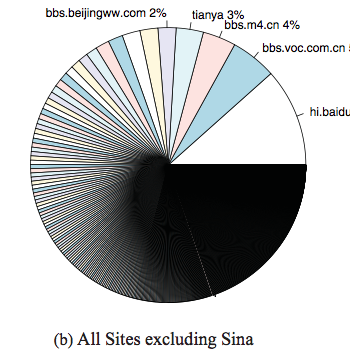
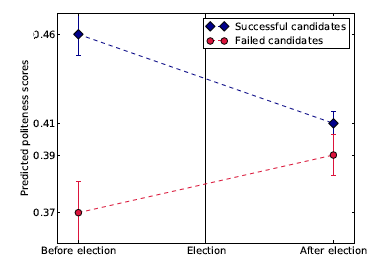
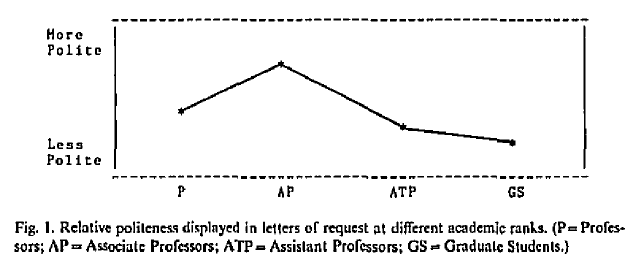
- Hu, Nan, Ling Liu, and Jie Jennifer Zhang. “Do online reviews affect product sales? The role of reviewer characteristics and temporal effects.” Information Technology and Management9.3 (2008): 201-214.
The paper discusses an interesting study that tries to link customer reviews with product sales on Amazon.com, while taking into account the temporal nature of customer reviews. The authors present evidence for the fact that the market understands the difference between favorable and unfavorable news (reviews), therefore bad news (review) would lead to lower sales and vice versa. The authors also find that consumers pay attention to reviewer characteristics and like reputation and exposure. Hence, the hypothesis that higher quality reviewers will drive the sales of a product on e-commerce avenues. The authors use Wilcoxon Z-statistic and multiple regression to support their findings.
First, it would be interesting to see if a review coming from a reviewer who has actually purchased the product (a “verified purchase”) has more impact on the product sales than one coming from someone who hasn’t purchased the product. This is one of the things I look for when using Amazon.com. Another aspect is that products like Books, DVDs and Videos are neither consumables nor necessities. What I mean is that, people can have very particular tastes when it comes to what they read and watch. For example, Alice might be a big fan of Sci-Fi movies while Bob might like Drama more. In my opinion the sales for these products would depend more on what the distribution of these “genre-preferences” are like in the market (i.e. people who have the time and money to relish these products). It would be interesting to re-do this study with a greater variety of product categories. I feel that reviews would play a much bigger role when it comes to the sales of products like, consumables (for e.g., groceries, cosmetics, food) and necessities (for e.g., bags, umbrellas, electronics) because almost everyone “needs” these products and trusted online reviews would act as a signal for the quality of these products. It would be interesting to verify this intuition.
Second, given the authors mention bounded rationality and opportunism, I feel that when buying a product on Amazon.com, it is very unlikely that I would look for the “reputation/quality” of the reviewer before making a purchase. Again, what would matter the most for me is if the review is coming from an actual customer (a verified purchase). Additionally, the amount of time I would spend researching a product and digging into it’s reviews is directly proportional to the cost of the product. Also, the availability of discounts, free shipping, etc. can greatly bias my purchase decisions. I am not sure whether classifying reviewers as high/low quality and products as high/low-coverage based on the median of the sample is a good idea. What happens to those who lie on the median? Why choose the median? Why not the mean? Moreover, it would be interesting to see the distribution of sales-rank over the three product categories. Do these distributions follow a power law?
In summary, I enjoyed reading the paper and feel that it was very novel for 2008 and as the authors mention, the work can be extended in various ways now that we have more data, computing power and analysis techniques.