Topic: Bots & Sock puppets
Definitions:
Sockpuppets: “fake persona used to discuss or comment on oneself or one’s work, particularly in an online discussion group or the comments section of a blog” [3]. Paper [1] defines it as “a sockpuppet as a user account that is controlled by an individual (or puppetmaster) who controls atleast one other user account.” They [1] also use the term “sockpuppet group/pair to refer to all the sockpuppets controlled by a single puppetmaster”.
Bots: “Internet Bot, also known as web robot, WWW robot or simply bot, is a software application that runs automated tasks (scripts) over the Internet.” [4]
Summary [1]
The authors [1] study the behavior of sockpuppers. The research goal is to identifying, characterizing, and
predicting sockpuppetry. This study [1] spans across nine discussion communities. They demonstrate that sockpuppets differ from ordinary users in terms of their posting behavior, linguistic traits, as well as social network structure. Moreover, they use the IP addresses and user session data and identify 3,656 sockpuppets comprising 1,623 sockpuppet groups, where a group of sockpuppets is controlled by a single puppetmaster. For instance, when studying “avclub.com”, the authors find that sockpuppets tend to interact with other sockpuppets, and are more central in the network than ordinary users. Their findings suggest a dichotomy in the deceptiveness of sockpuppets: some are pretenders, that masqueradeas separate users, while others are non-pretenders, that is sockpuppets that are overtly visible to other members of the community. Furthermore, they find that deceptiveness is only important when sockpuppets are trying to create an illusion of public consensus. Finally, they create a model to automatically identifying sockpuppetry.
Reflections [1]
Of the 9 nine discussion communities that were studied, their is a heterogeneity with respect to: a) the “genre”, b) the number of users and c) the percentage of sock-puppets. While these are interesting cases to study, none of them are “discussion forums”. Their main function as websites, and business model, is not to be a discussion platform. This has several ramifications. For instance, “ordinary” users, and possibly moderators, who are participating in such websites might find it more harder to identify “sock-puppetry”, because they can not observe their long-term behavior, as they could in a “discussion forum”.
Their analysis focuses on sockpuppets groups that consist of two sockpuppets. However, neither sockpuppets groups that consist of three or even four sockpuppets are not neglible. What if these sockpuppets demonstrate a different pattern? What if a multitude of sockpuppets of 3, 4 and beyond, is more likely to engange in systematic propaganda? This is a hypothesis that would be interesting to explore.
I also believe that we can draw some parallels from this paper with another paper that we reviewed in this class regarding “Antisocial Behavior in Online Discussion Communities” [5]. For instance, their definitions are different regarding the definition of “threads” etc. As a matter of fact, two of the authors in both papers are the same, [1] Justin Cheng and Jure Leskovec. Furthermore, in both papers they use “Disqus”, which is the commenting platform that hosted these discussions. Would the results generalize in something else than “Disqus”? This, I believe, remains a central question.
The “matching” by utilizing the propensity score is questionable. The propensity score is a good matching measure only when we account/control for all the factors i.e. we know the “true” propensity score. This does not happen in the real world. It might be a better idea to add “fixed-effects” and restrict the matches to a specific time wedge, i.e. match observations within the same week to control for seasonal effects. The fact that the dataset is “balanced” after the matching does not consist of evidence that the matching was done correctly. It is the features they used for matching (i.e. “the similar numbers of posts and make posts to the same set of discussions“) that should be balanced, not the “dataset”. They should have had at least a QQ plot that shows the ex-ante and ex-post matching performance. A poor matching procedure will result into bad inputs into their subsequent machine learning model, in this case random forest. Note that the authors performed the exact same matching procedure in their previous 2015 paper [5]. Apparently nobody pointed this out.
Questions [1]
[Q1] I am curious as to why the authors decided take the following action: “We also do not consider user accounts that post from many different IP addresses, since they have high chance of sharing IP address with other accounts“. I am not sure whether I understand their justification. Is their research that backs up this hypothesis? No reference is provided.
In general, remove outliers, for the sake of removing outliers, is not a good idea. Outliers are removed usually when a researcher believes when a specific portion of the data is an wrong data entry i.e. a housing price of $0.
[Q2] A possible extension would be to explore the relationship beyond sockpuppets groups that consist of only two sockpuppets.
[Q3] There is no guarantee that the matching was done properly, as I analyze in the reflection.
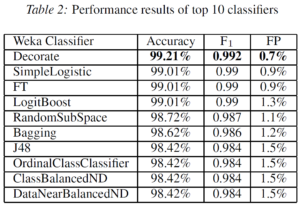
The authors propose and evaluate a novel honeypot-based approach for uncovering social spammers in online social systems. The authors define social honeypots as information system resources that monitor spammers’ behaviors and log their information. The authors propose a method to automatically harvest spam profiles from social networking communities, the development robust statistical user models for distinguishing between social spammers and legitimate users and filtering out unknown (including zero-day) spammers based on these user models. The data is drawn from two communities, MySpace and Twitter.
While I was reading the article, I was thinking of the IMDB ratings. I have observed that there have been a lot of movies, usually controversial, that receive ratings only ratings that in the extremes of the rating scale, either “1” or “10”. Or in some other cases, movies are rated, even though they have still not been publicly released. Which fraction of that would be considered a “social spam” though? Is a mobilization of an organized group that is meant to down-vote a movie a “social spam” [6]?
Regardless, I think it is very important to make sure ordinary users are not classified as spammers, since this could have a cost on the social networking site, including their public image. This means that their should be an acceptable “false positive rate”, tied to the trade-off between between having spammers and penalizing ordinary users, a concept known in mathematical finance as “Value at risk (VaR)”.
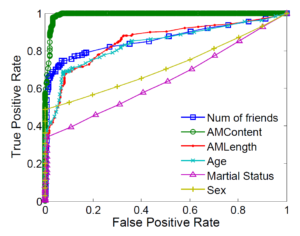
Something that we should stress is that in the MySpace random sample, the profiles have to be public and the about me information has to be valid. I found the interpretation of the “AboutMe” feature as the best predictor given by the authors very interesting. As they argue, it is the most difficult feature for a spammer to vary because it contains the actual sales pitch or deceptive content that is meant to target legitimate users
[Q1] How would image recognition features perform as predictors?
[Q2] Should an organized group of ordinary people who espouse an agenda be treated as “social spammers”?
References
[1] Kumar, Srijan, et al. “An army of me: Sockpuppets in online discussion communities.” Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2017.
[2] Lee, Kyumin, James Caverlee, and Steve Webb. “Uncovering social spammers: social honeypots+ machine learning.” Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2010.
Read More