Paper:- The Language that Gets People to Give: Phrases that Predict Success on Kickstarter
Summary:
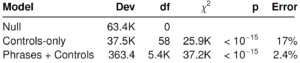
This paper looks into the language usage and its predictive power of getting funded in a Crowdfunding site, Kickstarter. Previous studies already found several factors that affect funding probability in such sites, like higher funding goal, longer project duration, video in a project pitch, social network, key attributes of the project etc. This study builds on that by adding linguistic analysis of the project pitch. The authors apply the unigram, bigram, and trigram phrases common in all 13 categories of projects as linguistic predictive variables along with 59 other Kickstarter variable into a penalized logistic regression classifier. Finally, authors do both qualitative and quantitative analysis of the result of the output. Authors provide top 100 phrases that contributed to their algorithm. From the qualitative analysis, several intuitive phenomena appear like reciprocity and scarcity have positive correlation with being funded. Several other factors like social identity, social proof, and authority also seem to contribute to the process. LIWC analysis suggests that funded project pitch includes higher cognitive process, social process, perception rates etc. Although sentiment analysis shows that funded projects have higher positive and negative sentiment, it is not statistically significant. One interesting phenomenon found in the analysis was that a completely new project is likely to have less success than one that builds on a previous one.
Reflection:
The paper provides a good motivation for the analysis of linguistic features in Crowdfunding projects. The authors use of Penalized logistic regression seemed interesting to me. I would have probably thought of applying PCA first and then doing a logistic regression. But Penalized logistic regression provided results which were important for interpretation. At the same time, looking into the top 100 positively and negatively correlated terms reminds about the fault of big data interpretation: “seeing correlation where none exists”. For example, “Christina”,”cats” etc. For the sake of generalizability, authors lose many terms which could have better correlation with projects. But the beta score of the 29 control variables says otherwise. Authors’ use of Google’s 1T corpus for reducing the number of phrases and tree visualization of some common terms were nice additions to the paper. Although positively correlated terms don’t guarantee success in a Crowdfunding project, negatively correlated terms provide a list of things to avoid in the project pitch which is very useful. The social proof attribute of the result begs the question, can we manipulate the system by faking backers?