Both of the papers assigned for today deal with computational linguistics revolving around politeness and repectfulness:
- Danescu-Niculescu-Mizil, C., Sudhof, M., Jurafsky, D., Leskovec, J., & Potts, C. (2013) “A computational approach to politeness with application to social factors”.
- Voigt, R., Camp, N. P., Prabhakaran, V., Hamilton, W. L., Hetey, R. C., Griffiths, C. M., … & Eberhardt, J. L. (2017) “Language from police body camera footage shows racial disparities in officer respect”.
I’m going to talk about the second one first because it seems to tackle a more interesting topic and asks a hard question with serious social consequences. The authors question whether black people are systematically treated differently(with less respect) by police officers? and the answer, alarmingly, is yes.
However, i don’t think the authors catered for the drastic difference in crime rate in Oakland as compared to the national average and this makes generalizability of the study a major concern.
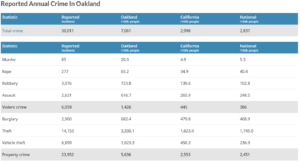
So my question is then is that “does the oakland police department have a problem of racial profiling or do police departments in general exhibit this trend?” it’s very important to realize the difference and it’s an easy one to overlook. Another important aspect that is missing, and is pointed out by the authors as well is that the while the trends may be obvious, the reasons thereof are not! which i believe are quite important.
Finally i think without taking the language, body language and facial expressions of the people being questioned, the study might paint an incomplete picture. With modern deep-learning techniques and out of the box solutions for object detection, facial segmentation etc. such analysis is now possible. Hence, while I feel that this study is a step in the right direction but it’s one which needs much more work.
Coming back to the first paper, before i get into the paper itself, just by reading the abstract the question the comes to mind is whether models such as the one proposed by the authors have the potential to be used for language policing and how intrusive could the effect be on freedom of speech? The reason why i raise this question, is that while we are heavily concerned about whether people face opinion-challenging information online so as to not create “echo chamber”, we tend to have the opposite stance on language used which possibly has the potential to create a “slowflake culture”. In my opinion negative experience are necessary for growth.
Nevertheless going back to the paper itself, the most interesting trends were from the stack-overflow results showing that people become less polite (haughty?) after gaining non-monetary affluence and that they becomes more polite when they loose. I guess the former goes along the lines of “humility is a hard attribute to find?”. Though i think the analysis is too one-dimensional in the sense that formality and or the necessary strictness that is required of someone when in position of power, might be perceived as less polite but no less respectful? I think a separate set of experiments needs to be run to confirm this observation and so i wouldn’t treat this particular results as a really interesting hypothesis and nothing more. Perhaps popularity of users and politeness could also be studied in a different set of experiments.
Another subtle point that the paper missed is that English is now becoming (probably has already become) a universal language and the way it’s used differs quite widely among different cultures and geographic. This seems to be a repeating trend among the papers we’ve read so far in the class. The question here becomes then what kind of effects do the local languages have on the perception of respect in (translated?) English?It may be the case that phrases when translated over from the local language to English become less-polite or maybe even rude.
Finally, i was wondering how well the study would fare with more modern NLP techniques which capture not only sentence structure but also inter sentence relationship (the proposed classifier doesn’t do that right now) and would the findings still hold or get augmented.