Paper 1 : The Promise and Peril of Real-time Corrections to Political Misconceptions
Paper 2 : A Parsimonious Language Model of Social Media Credibility Across Disparate Events
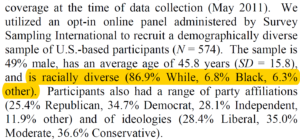
Both papers deal with user opinions on information accessed on the Internet, especially news articles. The first paper shows that the individuals exposed to real-time correction to the news articles they are reading, are less likely to be influenced by the corrections if it goes against their belief system. On the other hand, it is effective if the correction goes with their beliefs. The paper goes into details into explaining that more emotionally invested a user in the topic of an article, less likely he/she is going to be swayed by the correction whether it is real-time or delayed. Users get more defensive in such cases especially if the counterargument is provided in real-time. The acceptance rate of counterargument is a little better if they are presented after a delay to the user. I can understand that a delay can provide the reader with time to introspect his/her beliefs on the topics and may raise curiosity for counterarguments. However, will all kind of delays have that effect ? Human attention span is pretty low and it may happen when the correction is introduced to the user, the user may not remember the original article but only its summarized judgments and the correction may not have a strong effect on it. I liked the part of the paper where they discussed how users only keep summary judgment of attitude and beliefs and discard the evidences. When presented with counterarguments, they decide whether the new idea is persuasive enough to update old beliefs, paying little attention to the facts provided by the article or its source. I think that the readers will trust a counterargument to deeply held beliefs more if it comes from sources which they already trust. Similar observation has been made in paper which adds that the framing of the counterargument is also very important. A counterargument which is respectable of the reader’s beliefs will have a greater impact.
The second paper introduces the factor of the language model used in credibility of a news articles. Certain words reduce credibility and other increase credibility. Such research is quite important, however, it doesn’t take into account external factors like the personal beliefs and attitude of the reader, his/her political and social context etc. Even though paper makes a case of certain words of assertiveness which cause increased credibility, it cannot be generalized. For some people, assertive opinions which are go against their beliefs might appear less credible than opinions which shows ambiguity and reasoning of both sides of the arguments. A good direction of research from the second paper should be inclusion of diversity factors into credibility account. Different factors like gender, race, economic and social status, age etc. could vary the results.
An example of different result would be a research on similar topic was done on reddit community changemyview. In changemyview, people ask to be provided with challenging views to their deeply held beliefs. The paper concluded that in most of the cases, language and the tone of the counterargument played a bigger role than quantity or quality of the facts. A counterargument which causes the reader to introspect and arrive on the same conclusion as the counterargument will be highly influential in changing reader’s view. It also makes a point that only those people who are ready to listen to counterarguments participate in that community. Hence, the people who decide to stay in their echo chamber are not evaluated in the study.