[1] Nguyen, Thin, et al. “Using linguistic and topic analysis to classify sub-groups of online depression communities.” Multimedia tools and applications 76.8 (2017): 10653-10676.
In this paper, Nguyen et al. use linguistic features to classify sub-groups of online depression communities. The dataset that they use is of Live Journal and is comprised of 24 communities and 38,401 posts. These communities were grouped into 5 subgroups: bipolar, depression, self-harm, grief, and suicide. The authors built 4 different classifiers and Lasso performed the best. First of all, the size of the dataset is very small and secondly, I don’t mind the use of Live Journal but most of the papers that were similar to this topic performed their studies on multiple platforms because it is possible that they got their results due to the certain specific characteristics of Live Journal platform.
I am pretty sure that this paper was a class project given the size of data the way they performed modeling. First, the authors labeled the data themselves that can induce some bias and secondly, the major put off was that they used 4 different classifiers instead of using multi-class classifier. I wish they had a continuous variable 😉
Finally, my biggest criticism is that why the 5 subgroups were created because self-harm, grief, suicide etc. are a result/cause of depression and therefore, the claim in the paper that “no unique identifiers were found for the depression community” verifies my argument. The subgroups, which are the basis of entire paper do not make sense to me at all.
[2] Felbo, Bjarke, et al. “Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion, and sarcasm.” arXiv preprint arXiv:1708.00524 (2017).
In this paper, Felbo et al. build an emoji predictor named DeepMoji. The authors build a supervised learning model on an extremely large dataset of 1.2 billion tweets to classify the emotional sentiment conveyed in tweets with embedded emoji. The experiments showed that DeepMoji outperformed state of the art techniques for the specific dataset.
My first reaction after looking at the size of the dataset was “Woah!! They must have supercomputers”. I wonder how long did it take for their model to train. The thing that I liked the most about this paper was that they provided a link to a working demo (https://deepmoji.mit.edu). Given that I had a hard time understanding the paper, I spent a lot of time playing around with their website and I can’t help but appreciate how accurate their model is. Here is one example that I tried for a phrase “I just burned you hahahahaha”, and it showed me the most accurate associated emojis.
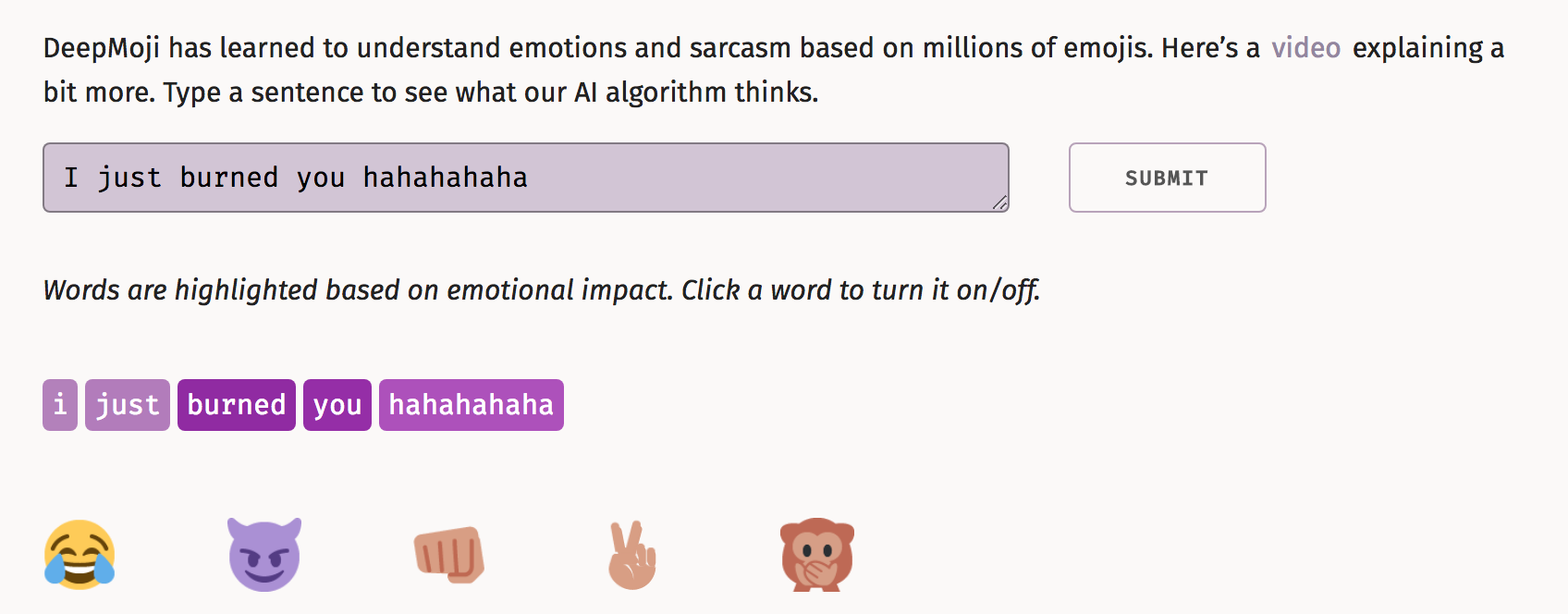
Now, when I removed the word ‘burned’, it showed me the following
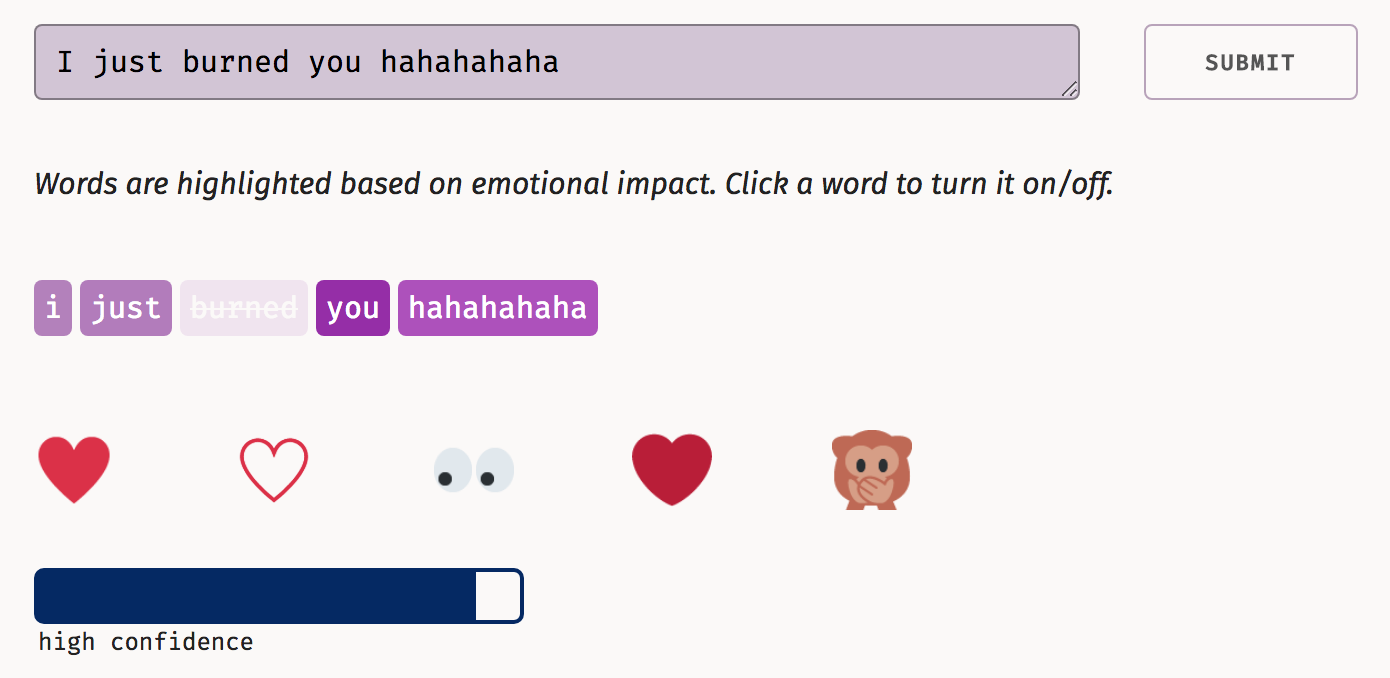
Due to my limited knowledge of deep-learning, I cannot say if there were flaws in their modeling or not, but it seemed pretty robust and the results of their tool show that robustness.
Anyway, I believe that this paper was very Machine Learning centric and had less to do with psychology.
Finally, the authors say in the video (https://youtu.be/u_JwYxtjzUs) that this can be used to detect racism and bullying. I would like to know how the emojis can help in that?