Well let me start out by saying that this was a fun read and the very first takeaway is that I know now how to “take away money” from people!
Anyhow, moving on to a more serious note, since the prime motive of the paper is to analyze the language used to pitch products/ideas and since videos (or content thereof) are a good indicator of Funded or not Funded, what effect does implicit racial bias of the crowd have? More concretely:
- What effect does the race of both the person pitching and the crowd have?
- Do people tend to fund people of the same racial group more?
Another aspect that I would like to investigate is the crowd itself and its statistics per funded project and how it varies across them? Can we find some trend there?
The paper more or less gives evidence of the intuitive insights both from literature and ones based on common sense e.g. people/contributors don’t stand to make profit or reap monetary benefit from the project but given some form of “reciprocation”, there’s added incentive for them to contribute apart from them liking the project. Sometimes this takes the form of something tangible like a free t-shirt and at other times it’s merely a mention in credits but the important point is that people are getting something in return for for their funding. Another prominent one is “scarcity” i.e. the desire to have something that is unique limited to only a few people. Tapping into that emotion of exclusivity and adding in personalization is good way to securing some funding.
However, not all is well! As was also noticed by some other people, there are some spurious phrases in table 3 and 4 for which it seems that they should’ve belong to the other category e.g:
- “trash” was in funded with beta = 2.75
- “reusable” was in not funded beta = -2.53
There were also some phrases which made no sense to be in either category e.g. “girl and” was in funded with $\beta$ = 2.0 ? I suspect that this highlights a flaw/poor choice of classifier. What would be a better classifier ? Something like word embeddings where the embeddings can be ranked?
Moving on to the model summaries provided:
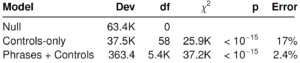
It’s quite evident that the phrases provide quite a big boost in terms of capturing the distribution of the dataset, so this makes me wonder, how a phrases-only model would perform? My guess is that it’s performance should be closer to the phrases + controls model than to the controls-only model. Though I’m going off a tangent but let’s say we don’t use logistic regression and opt for something more a bit more advanced e.g. sequence models or LSTMs to predict the outcome, would the model turn out to be better than the phrases+controls model? Also, will this model stand the test of time? i.e. as language or trends of marketing evolve, will this model hold true, say, 6-10 years from now? Since the paper is from 2014 and the data from 2012-2014, does the model hold true right now?
Another thing that the authors mentioned and that caught my attention is the use of social media platforms, and it’s raised quite a few questions:
- How does linking to Facebook affect funding? Does it build more trust among backers because it provides a vague sense of legitimacy?
- Does choice of social media platform matter i.e. Facebook vs Instagram?
- Does language of the posts have similar semantics or is it more click bait-ish?
- What affect does frequency of post have?
- Does the messaging service of Facebook pages help convince vary people to contribute?
This might make for a good term project.
I would also like to raise two technical questions, regarding the techniques used in the paper:
- Why penalized logistic regression? Why not more modern, deep learning techniques or even other statistical models e.g. multi-kernel based Naïve Bayes or SVMs?
- What is penalized in penalized logistic regression; does it refer to the regularize added to the RSS or likelihood?
- I understand Lasso results in automatic feature selection, but comparison with other shrinkage/regularization techniques is missing. Hence, the choice of the regularization method seems more forced than justified.
Finally, and certainly most importantly, I’m glad that this paper recognizes that:
“Cats are the Overlords of the vast Internets, loved and praised by all and now boosters of Kick Starter Fundings”