Both of the papers revolve around the theme of fake profile, albeit of different types.
- Kumar, Srijan, et al. “An army of me: Sockpuppets in online discussion communities.” Proceedings of the 26th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2017.
- Lee, Kyumin, James Caverlee, and Steve Webb. “Uncovering social spammers: social honeypots+ machine learning.” Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval. ACM, 2010.
The first paper about sockpuppets is well written and pretty well explained throughout. However, the motivation of the paper seems weak! i see that there are ~ 3300 socketpuppets out of a total of ~2.3 million users! So that bring me to my question that is that even worthy enough problem to tackle? Do we need an automated classification model? why do socketpuppets need to be studied? Do they have harmful effects that need to be mitigated?
Moving forward, the entirety of the paper builds up to a classifier and though not a bad thing, I get a feeling that the work was conducted top down (idea of a classifier for sockpuppets -> features needed to build it) but the writing is bottom up (need to study sockpuppets and the use of the generated material to make a classifier). Regardless, the study does raise some follow up questions, some of which seem pretty interesting to check out:
- Why do people make sock puppets? What purpose are the puppets are being used for? are they created for a targeted objective or are they more troll like (just for fun? or just because someone can?)
- How do puppeteers differ from ordinary users?
- Can community influence the creation of sockpuppets? I realize the paper already partially answer this question, but i think there needs to be much more dialed down attention on temporal effects of community on, and the behavior of, a puppeteer before the creation of the puppets)
Coming onto the classifier, I have a few grievances. Like many other papers that we have discussed in class, the paper lacks the details of the classifier model used e.g. number of tress in the ensemble, the max tree depth, what’s the voting strategy: do all tress get the same vote count?. However, I will give the authors credit because this is the first paper among the ones we’ve read that has used a powerful classifier as opposed to simple logistic regression. Still, the model has poor predictive power. Since, i’m working on an NLP classification problem i’m wondering if the sequential models might work better.
Moving onto the second paper, it’s a great idea but executed poorly and so, I apologize for the harsh critique in advance. The idea of honeypot profiles is intriguing but just like how social features can be used to sniff out spammer profiles, they can used to sniff out honeypots and hence, the trap can be avoided. So I think the paper’s approach is naive in the sense that it needed more work on why and how the social honeypots are more robust to changes in strategies by the spammers.
Regardless, the good thing about the project is the actual deployment of the honeypots. However, the main promise of being able to classify the spammer and non-spammers has not been delivered. The scale of the training dataset is minuscule and not representative i.e. there are only 627 deceptive and 388 legtimate profiles for the MySpace classification task. Hence, the validity of the following table becomes questionable.
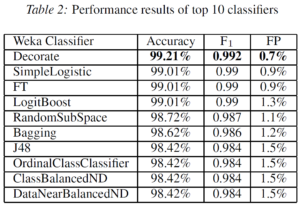
With the dataset of the same scale as the one being used here, we could’ve also fitted a multinational regression and perhaps gotten similar results. The choices of the classifiers has not been motivated and why have so many been tested?. It seems the paper has fallen victim to the approach that “when you have a hammer everything looks like a nail”. The same story is repeated with the twitter classification task.
Regardless of my critique, the paper presents the classifier results in more detail than most papers, so that’s a plus. It was quite interesting to see that age in figure 2 (show below) had a big ROC. So, my question is that are the spammer profiles younger than legitimate user profiles?
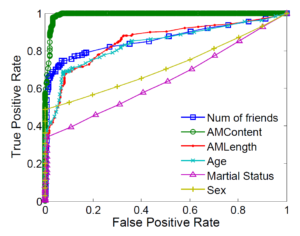
Another, question is regarding the test of time for the study, will a similar classifier perform well on the MySpace of today (i.e. Facebook)? Since, the user base now is probably much different and diverse now, the traits of legitimate users have changed.
Finally, I would like other people’s opinion on the last portion of the paper i.e. “in-the-wild” testing. I think this last section is just plain wrong and misleading at best. The authors say that
“… the traditional classification metrics presented in the previous section would be infeasible to apply in this case. Rather than hand label millions of profiles, we adopted the spam precision metric to evaluate the quality of spam predictions. For spam precision, we evaluate only the predicted spammers (i.e., the profiles that the classifier labels as spam). …”
Correct me if I’m wrong please but the spam precision metric proposed is measuring the true positive rate for the profiles that were actually classified as spam and not the ones that were actually spam. This is misleading because it ignores the profiles that weren’t detected in the first place and so for all we know, the true-negatives may have been orders of magnitude larger than the detected negatives. For Example, suppose in actuality we had 100000 spam profile in 500000 overall profiles, out of which only 5000 were detected. The authors are only reporting how many of the 5000 were actually true positives and not how many of the 100000 were true positive. There is no shortcut to research and i think the reason cited above in italics is simply a poor excuse to avoid a repetitive and time consuming task. In the past few years, good data is what has driven Machine Learning to it’s current popularity and so to make a claim using ML, the data needs to be to a great degree unquestionable. It’s for the same reason that most companies don’t mind releasing their deep learning model’s architecture because they know that without the data that the company had, no one will be able to reproduce similar results. Therefore, to me all the results in section 5 are bogus and irrelevant at best. Again I apologize for the harsh critique.