[1] R. M. Bond et al., “A 61-million-person experiment in social influence and political mobilization,” Nature, vol. 489, no. 7415, pp. 295–298, 2012.
[2] J. E. Guillory et al., “Editorial Expression of Concern: Experimental evidence of massive scale emotional contagion through social networks,” Proc. Natl. Acad. Sci., vol. 111, no. 29, pp. 10779–10779, 2014.
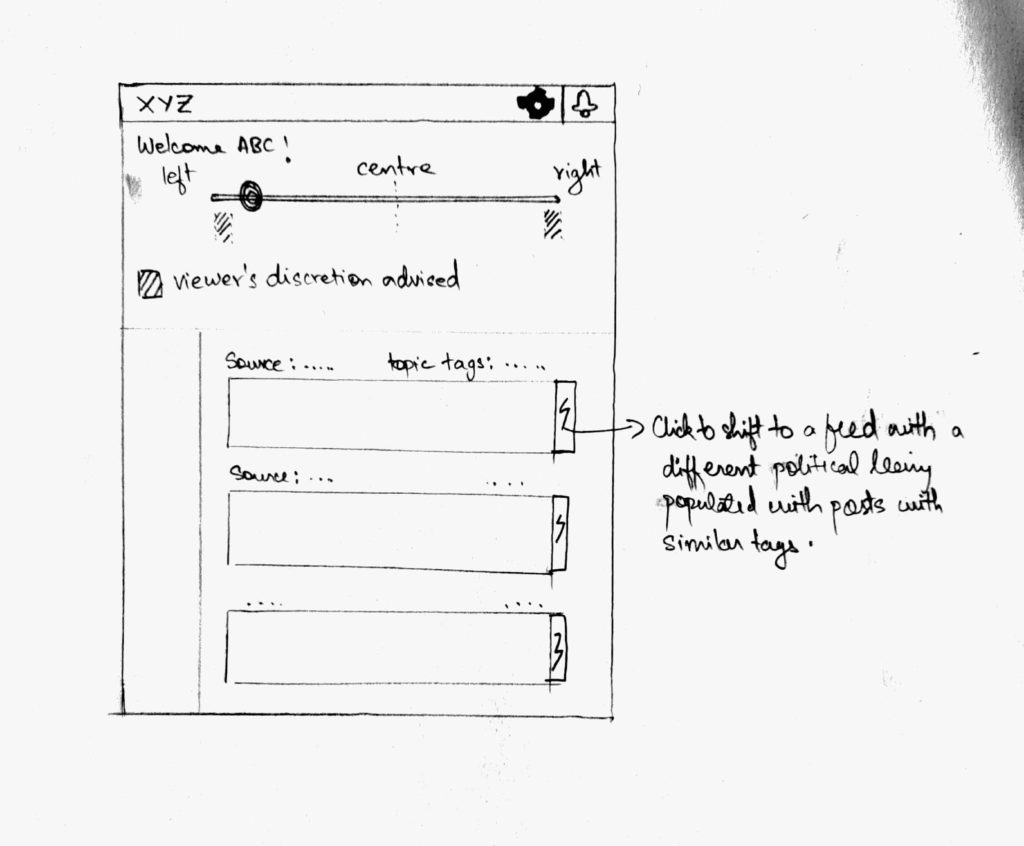
<Jots>
<1>
Ethical issues abound.
<2>
When one observes (key word) a close friend to be in a negative mood, we internally pick one of two choices: fight or flight (broader term: arousal).
Given, if the connection is strong, the probability of choosing the former, fight, will be high.
Although, the probability is dependent on the psychological character of the actor, given that most of us belong to one that exhibits positive attitude towards helping people fall into a category that would “fight.”(assumption may be challenged)
Given, the above, our minds go into a state which is ideal from helping another combat certain issue. This state allows one to put oneself in another’s shoe: empathy.
Can being in this state reflect in oneself?
If so, isn’t it a good characteristic, one that makes us human?
<3>
But how does one separate empathy for a close few from a group.
Can this empathy turn into allegiance leading to group thinking?
Is censorship a good way to tackle this? As a proponent of democracy I don’t think so.
Such effects can be negated through more diverse opinions in the public forum. But isn’t this affected by entities that restrict the access to these channels.
<4>
Also, doesn’t it mean there is a lack of forums which are designed to be available for everyone. Designed to be fair. This is definitely a moonshot as “human forum” (society) evolving for millennia hasn’t found the global optima (solution). But, this shouldn’t be a deterrent.
<5>
If one is pushed into a negative mood valance, would you be able to understand another’s state? Study [3] shows we’re less able to resonate with other people’s pain when we’re feeling down. Wouldn’t this mean the assumption of the authors of [2], of having equal probability of sharing information by a person being subjected to the experiment is wrong?
[3] Li, X., Meng, X., Li, H., Yang, J. and Yuan, J., 2017. The impact of mood on empathy for pain: Evidence from an EEG study. Psychophysiology, 54(9), pp.1311-1322.