PAPER:
Danescu-Niculescu-Mizil, C., Sudhof, M., Jurafsky, D., Leskovec, J., & Potts, C. (2013). A computational approach to politeness with application to social factors.
SUMMARY:
In this paper, the authors put forth a computational framework for identification of linguistic cues of politeness on conversational platforms such as Wikipedia and Stack Exchange. They build a classifier that could annotate new request texts with close to human level accuracy. They put forth their findings on the relationship between politeness and (perceived) social status.
REFLECTION:
- Firstly, as the authors mention, the amount of politeness currency spent or ‘invested’ decreases the higher is a user’s perceived status. Now the question that can be asked is, why not do something, to ensure the same level of politeness exhibited by a user even after they rise in power and status.
- These online conversational systems do have markers and provisions for reputations and power and social status, but they fail to implement the same to emulate these concepts as in the real world.
- The stakes and motivation for a user to invest in politeness must be in proportion to his/her rank/power/reputation.
- There could be an alternate thought here, that this should not make it permissible for newbies to be less polite. And the point about raising the stakes does not insinuate that, this is because, as in the real world, an asker/imposer requesting for certain knowledge or services will still (have to) be polite considering the social norms and their need of the said information or services.
- Very often, it also happens that people with high power or knowledge or statuses, are rude to new and naive users using sarcasm thus avoiding having to utter rude and/or ‘bad’ things. Thus, if sarcasm detection can be coupled with politeness classifiers, it would be a very robust and deployable system.
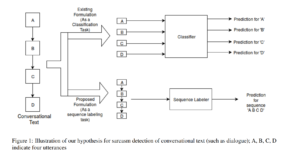
This paper by Joshi et al [1] gives a very innovative and interesting way for sarcasm detection, which provides a novel approach that employs sequence labelling to perform sarcasm detection in dialogue.
- Another potential approach that comes to mind for further improving and/or applying the identification of linguistic cues to identify politeness is in the domain speech recognition (via audio/video)
- One can make use of the intonations, the pauses, volumes and tones in speech combined with the content transcription of what is being said to train and better understand politeness in speech.
- Now, if the previously addressed problem, of sarcasm in conversational text, is addressed and handled, then one can definitely detect not only politeness but also sarcasm in speech.
- Lastly, Wikipedia and StackExchange are more or less similar platforms, but such an analysis can and should be carried out on platforms like Reddit and 4chan where each subreddit and thread has its different norms and tolerances for rudeness and politeness. Thus more insights and levels of tolerances can be understood with such an analysis on different platforms.
- Furthermore, it might be wise to perform an ethnographic analysis on the results of rudeness classifier to asses the norms and rudeness followed by different demographics since it is not the same for the entire population/userbase
[1] : Joshi, Aditya, Vaibhav Tripathi, Pushpak Bhattacharyya and Mark James Carman. “Harnessing Sequence Labeling for Sarcasm Detection in Dialogue from TV Series ‘Friends’.” CoNLL (2016).